扩展套餐
为需要更强大功能和专属支持的团队提供的高容量套餐。
享受更高的速率限制、更多并发浏览器和优先支持。
我们的 YouTube Scraper API(YouTube爬虫API)通过 Video Metadata Extraction(视频元数据提取)和 YouTube Transcript API(YouTube字幕API)提取完整的 YouTube 评论数据,包括 ID、内容、互动信息、Channel Stats Scraper(频道统计爬虫)和 Video Trends Data(视频趋势数据),支持全流程控制、无缝扩展与高效稳定表现。
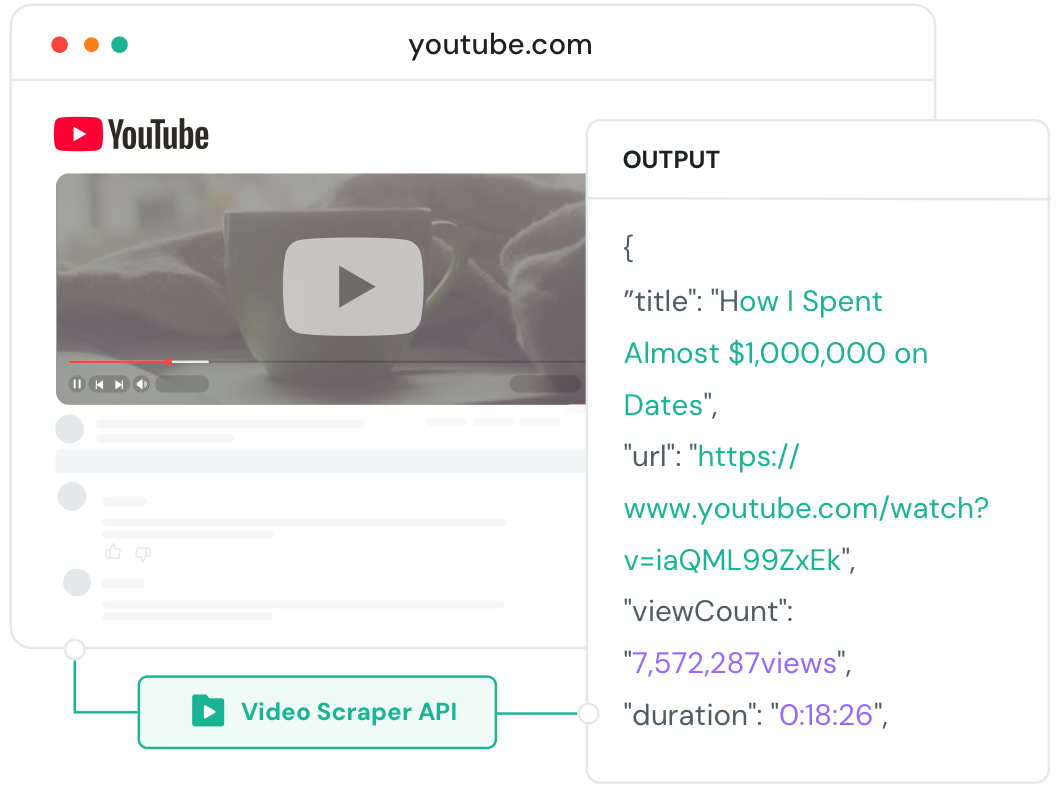
不再受限速、封禁或 yt-dlp 失败困扰。为 AI 训练提供稳定、PB 级的视频数据采集。
视频与音频下载 | 文本与字幕 | 完整视频评论 | 视频元数据 |
视频与音频下载 |
文本与字幕 |
完整视频评论 |
视频元数据 |
只需几个简单步骤即可获取清晰、结构化的 YouTube 数据。
01发现并评估视频 STEP1.1 使用视频 ID 或 URL 解析并访问视频资源 | 02下载视频与字幕 STEP2.1 下载视频/音频内容STEP2.2 获取视频字幕 | 03云端同步与导出 STEP3.1 自动上传数据到指定云存储STEP3.2 生成可共享链接并提供 API 访问 |
01发现并评估视频 STEP1.1 使用视频 ID 或 URL 解析并访问视频资源 |
02下载视频与字幕 STEP2.1 下载视频/音频内容STEP2.2 获取视频字幕 |
03云端同步与导出 STEP3.1 自动上传数据到指定云存储STEP3.2 生成可共享链接并提供 API 访问 |
透明的网页爬取定价,灵活的 API 订阅计划。比较数据提取成本,购买爬虫访问权限,免费开始 — 随业务增长而扩展。
为需要更强大功能和专属支持的团队提供的高容量套餐。
享受更高的速率限制、更多并发浏览器和优先支持。

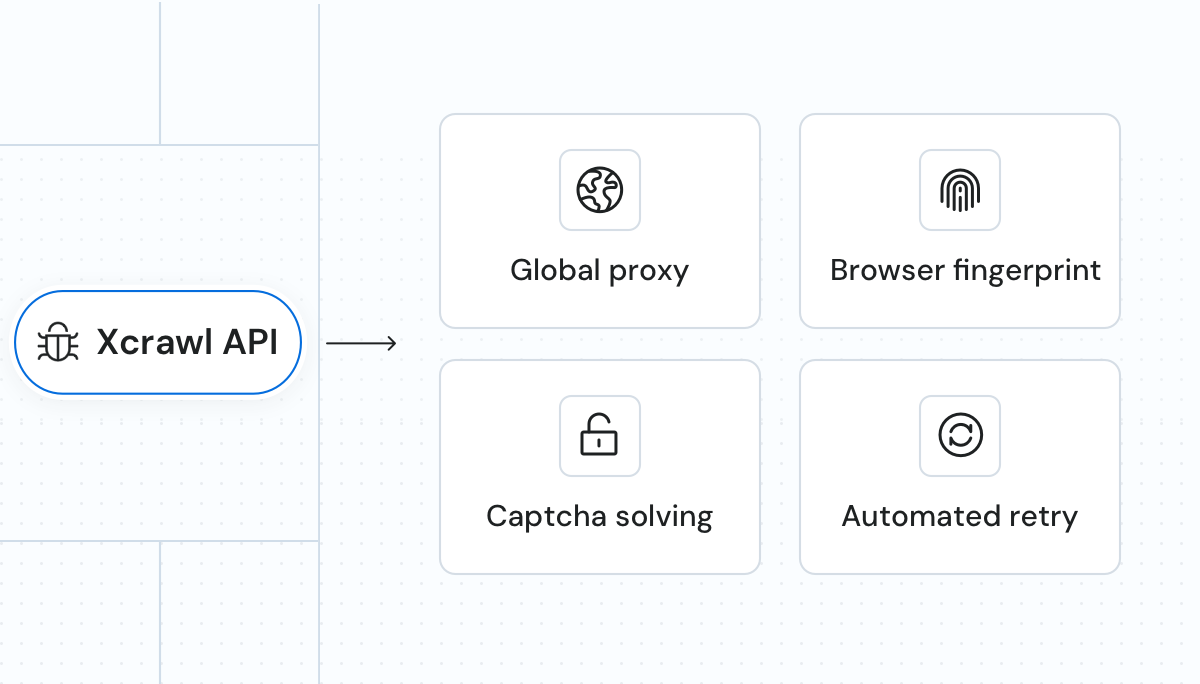
代理管理基于机器学习的代理选择与轮换,使用覆盖 190+ 国家/地区的高级代理池。 | AI 指纹伪装独特的 HTTP Header、JS 与浏览器指纹,使系统更适应动态内容。 | 验证码绕过自动重试与验证码绕过,确保数据持续获取不中断。 |
批量数据抓取可同时从多个页面提取数据,每批最多处理 1 万个 URL。 | 多种交付方式可通过 SFTP、AWS S3 等云存储接收数据,或通过 API 获取结果。 | 定时抓取设置自动化任务,按需定时采集数据,结果直接交付云存储。 |
免维护基础设施无需维护代理与采集系统,减少工程成本。 | 高扩展性易于集成,可按需求定制。 | 24/7 支持如遇问题,可随时获得专业支持。 |
代理管理基于机器学习的代理选择与轮换,使用覆盖 190+ 国家/地区的高级代理池。 |
AI 指纹伪装独特的 HTTP Header、JS 与浏览器指纹,使系统更适应动态内容。 |
验证码绕过自动重试与验证码绕过,确保数据持续获取不中断。 |
获取 LLM 就绪数据
我们提供结构化、AI 兼容的数据,使 YouTube 视频、字幕、元数据与搜索结果可无缝接入 LLM、AI 模型与分析工作流。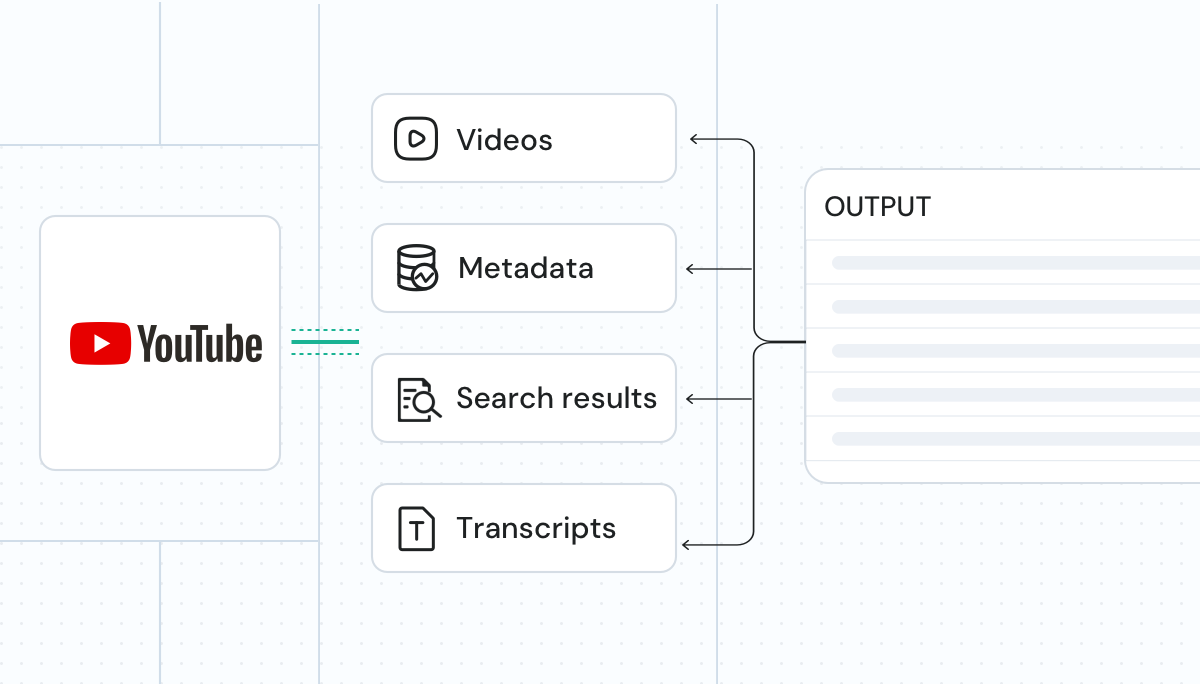
数据服务,无需维护。
访问来自全球真实流量的高质量视频数据了解关于 XCrawl 的一切信息。



