什么是 Scrape API?
Scrape API 是一款强大的工具,帮助用户快速从互联网中提取网页数据。只需一次 API 请求,Scrape API 即可自动处理数据提取、反爬虫机制、IP 代理等技术难题,返回结构化数据,免去繁琐的编码工作。
我们的爬取 API 结合了网页数据提取器、通用爬虫和网站解析 API,具备自动化爬取能力。轻松采集、分析并利用来自全网的数据,获取可执行的洞察,助力更明智的业务决策。这款强大的 API 专为需要大规模实时结构化数据的开发者、营销人员和企业而设计。
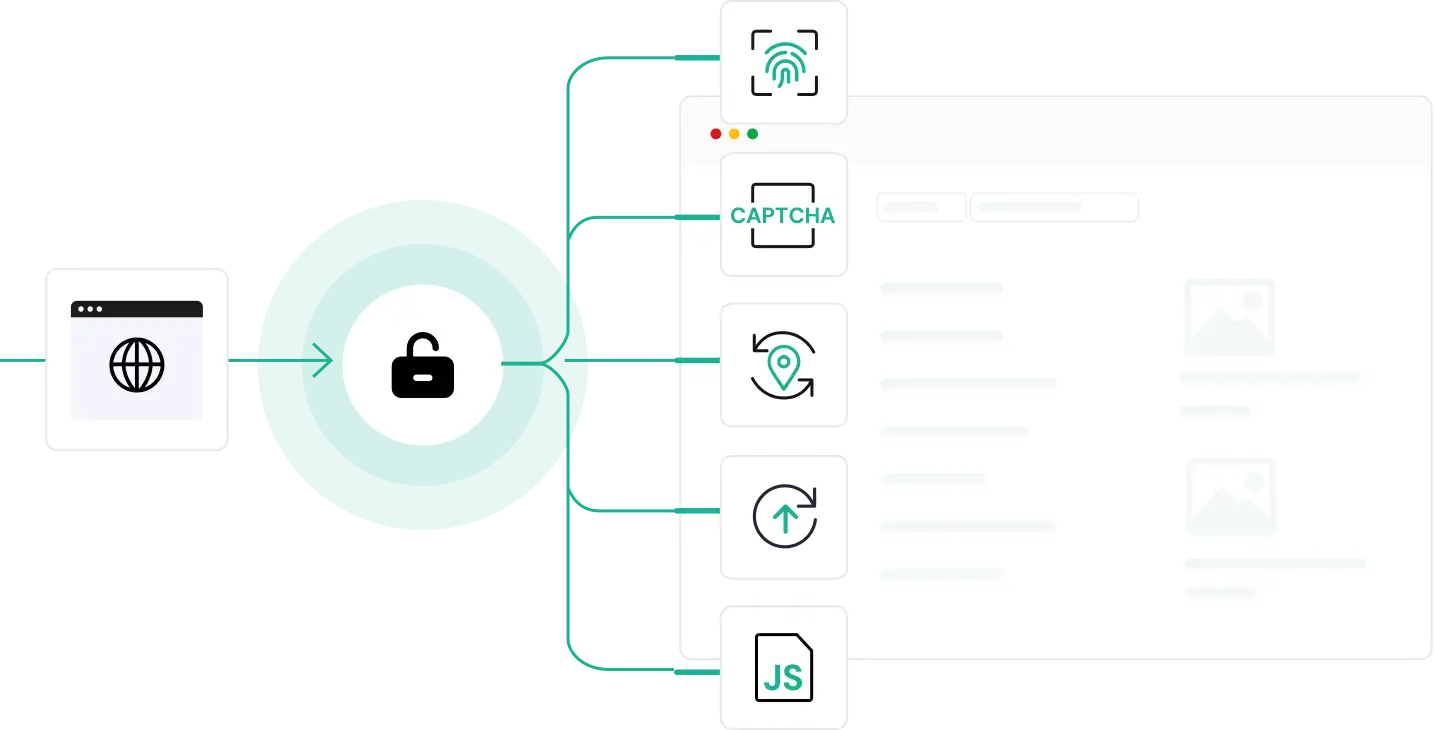
Scrape API 是一款强大的工具,帮助用户快速从互联网中提取网页数据。只需一次 API 请求,Scrape API 即可自动处理数据提取、反爬虫机制、IP 代理等技术难题,返回结构化数据,免去繁琐的编码工作。

从市场调研到 SEO —— 看看我们的 API 如何驱动真实世界的应用
通过 Scrape API,您可以自动从竞争对手的网站中提取产品信息,实现实时市场趋势监控,并及时应对竞争对手的价格变化。
Scrape API 可帮助您从多种信息来源(如新闻网站、社交媒体、论坛等)中提取行业相关文章、评论和问题等数据,用于情报分析。
Scrape API 可以抓取搜索引擎结果页面(SERP),帮助您提取竞争对手的排名、关键词和广告数据,从而优化您的 SEO 策略。
Scrape API 可协助从各类新闻网站、博客、论坛和社交媒体平台中提取内容,实现对新闻标题、财务报告或社交媒体动态的实时获取。
只需几行代码,即可轻松完成数据采集
透明的网页爬取定价,灵活的 API 订阅计划。比较数据提取成本,购买爬虫访问权限,免费开始 — 随业务增长而扩展。
为需要更强大功能和专属支持的团队提供的高容量套餐。
享受更高的速率限制、更多并发浏览器和优先支持。

自动绕过验证码、登录验证、IP 封禁等,无需人工干预。
实时轮换 IP,并模拟真实浏览器指纹,模仿人类行为,避免被识别为机器人。
内置动态渲染能力,轻松提取 JavaScript 密集型网站内容。
集成代理轮换与自动重试机制,确保高达 99% 的成功率。
仅对成功的数据提取进行计费——可将采集成本降低高达 30%。
严格的数据校验流程,确保您获得干净、结构化、可直接用于业务的数据。
加入开发者行列,使用 XCrawl 通过结构化网页数据驱动 AI 应用。从 1,000 免费积分开始。






了解关于 XCrawl 的一切信息。



