什么是爬取 API?
爬取 API 使开发者和数据团队能够以编程方式爬取整个网站或大型 URL 集。
它管理爬取逻辑、请求调度和反机器人保护,让您专注于数据提取而非基础设施。
我们的爬取 API 将 HTML 提取 API、原始页面爬虫和无头浏览器 API 整合到统一的网页爬虫接口中。专为大规模和定期的网络数据收集而设计,此爬取 API 让您定义一次爬取规则,即可自动收集数千或数百万页面的结构化数据。
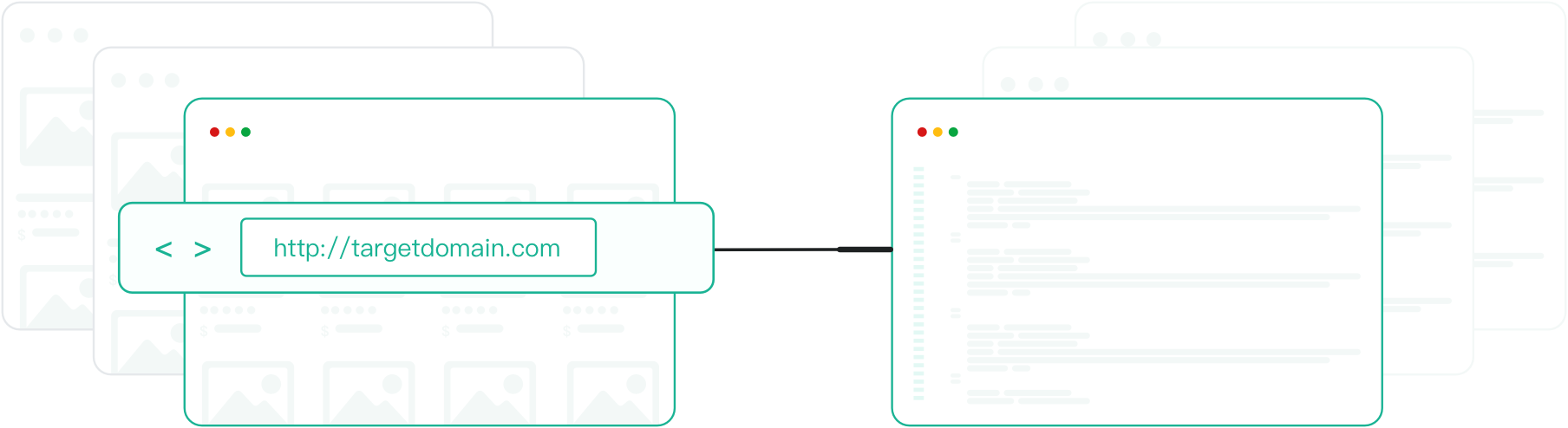
爬取 API 使开发者和数据团队能够以编程方式爬取整个网站或大型 URL 集。
它管理爬取逻辑、请求调度和反机器人保护,让您专注于数据提取而非基础设施。
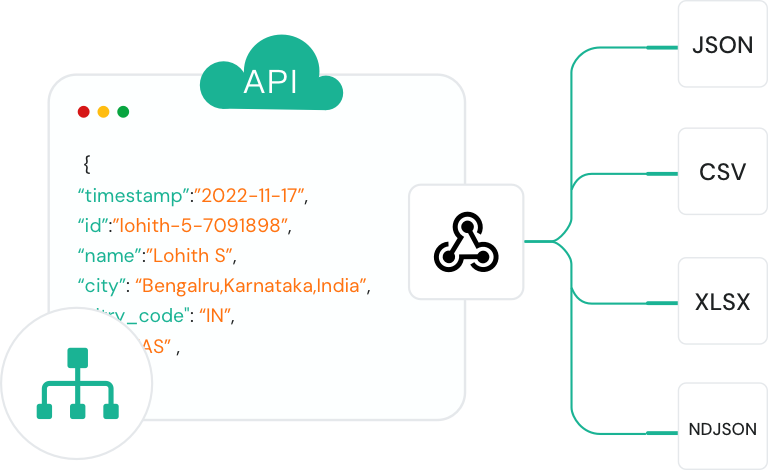
自动化跨网络的大规模数据收集
爬取 API 允许团队在整个网站上收集大量公共网络数据。它非常适合构建需要完整站点覆盖的数据集,例如产品目录、文章档案或目录式内容。
通过持续爬取竞争对手网站,企业可以监控价格变化、内容更新和产品发布。爬取 API 使检测趋势和快速响应市场变化变得容易。
爬取 API 帮助 SEO 团队大规模分析网站结构、内部链接、元数据和可索引性。通过爬取大量页面,团队可以识别技术问题并更有效地优化网站性能。
爬取 API 支持 AI 和机器学习工作流的长期数据收集。爬取的数据可以存储、按计划更新,并用于训练模型、知识库或大规模分析。
只需几行代码,即可轻松完成数据采集

透明的网页爬取定价,灵活的 API 订阅计划。比较数据提取成本,购买爬虫访问权限,免费开始 — 随业务增长而扩展。
为需要更强大功能和专属支持的团队提供的高容量套餐。
享受更高的速率限制、更多并发浏览器和优先支持。

专为高效可靠地爬取数千到数百万页面而设计。
通过 API 对爬取范围、深度和调度进行细粒度控制。
内置代理轮换和请求优化以避免封锁和禁止。
即使在高并发和长时间运行的作业下也能保持一致的爬取性能。
简单的 API 设计和清晰的文档,可快速设置和控制。
适用于分析、数据仓库和 AI 工作流的结构化爬取数据。
加入开发者行列,使用 XCrawl 通过结构化网页数据驱动 AI 应用。从 1,000 免费积分开始。






了解关于 XCrawl 的一切信息。



