Crawl API란?
Crawl API는 개발자와 데이터팀이 전체 웹사이트 또는 대규모 URL 세트를 프로그래밍 방식으로 크롤링할 수 있도록 합니다.
크롤링 로직과 요청 스케줄, 안티봇 보호를 관리하여 인프라 대신 데이터 추출에 집중할 수 있게 합니다.
Crawl API는 HTML 추출, 원본 페이지 스크래핑, 헤드리스 브라우저 기능을 통합한 웹 크롤러 인터페이스입니다. 대규모/주기적 웹 데이터 수집을 위해 설계되어 한 번 규칙 설정으로 수천만 페이지의 구조화 데이터를 자동으로 수집할 수 있습니다.
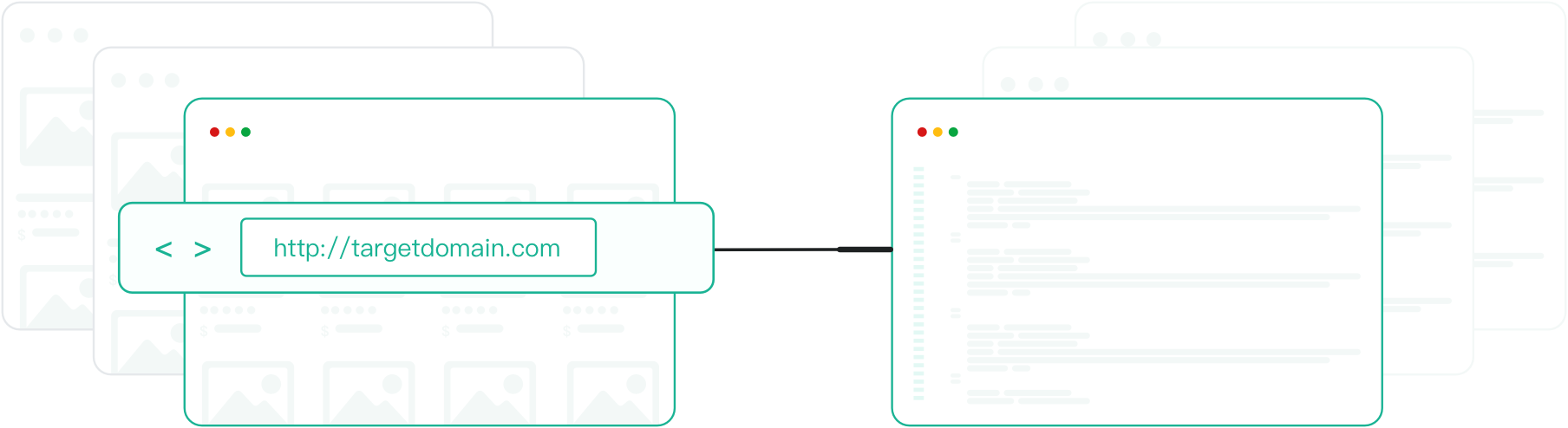
Crawl API는 개발자와 데이터팀이 전체 웹사이트 또는 대규모 URL 세트를 프로그래밍 방식으로 크롤링할 수 있도록 합니다.
크롤링 로직과 요청 스케줄, 안티봇 보호를 관리하여 인프라 대신 데이터 추출에 집중할 수 있게 합니다.
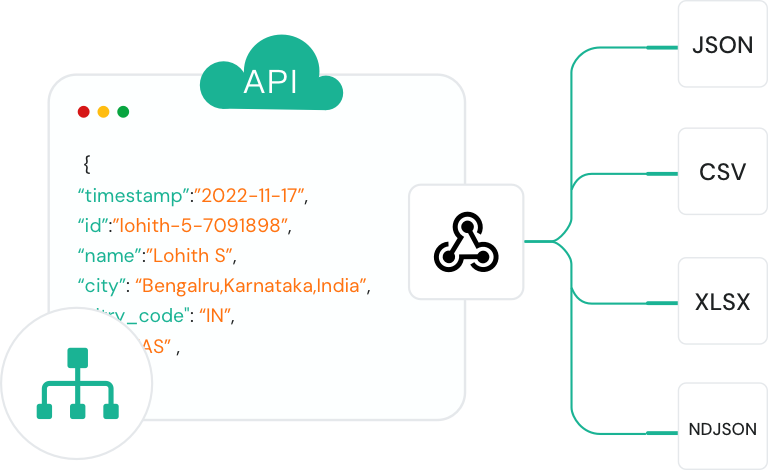
웹 전반의 대규모 데이터 수집 자동화
Crawl API는 팀이 대용량의 공개 웹 데이터를 전체 사이트 단위로 수집할 수 있도록 지원합니다. 상품 카탈로그, 기사 아카이브, 디렉토리 등 전체 커버리지 데이터셋 구축에 적합합니다.
경쟁사 사이트를 지속적으로 크롤링하여 가격 변동, 콘텐츠 업데이트, 신제품 출시에 빠르게 대응할 수 있습니다.
Crawl API로 SEO 팀은 대량의 페이지 구조, 내/외부 링크, 메타데이터, 인덱싱 여부 등을 분석하고 성능을 극대화할 수 있습니다.
장기적 AI·머신러닝 워크플로우용 데이터 수집을 지원합니다. 수집된 데이터는 스케줄 기반 업데이트, 모델 학습, 대규모 분석에 활용할 수 있습니다.
단 몇 줄의 코드로 데이터 추출 완성

투명한 웹 스크래핑 가격정책, 유연한 API 구독제. 데이터 추출 비용 비교, 크롤러 액세스 구매, 무료로 시작해 성장에 맞춰 확장하세요.
더 많은 파워와 전담 지원이 필요한 팀을 위한 대용량 요금제.
더 높은 속도제한, 더 많은 동시 브라우저, 우선 지원을 누리세요.

수천~수백만 페이지도 빠르고 안정적으로 크롤하도록 설계되었습니다.
API로 크롤 범위, 깊이, 일정까지 세밀하게 컨트롤
내장 프록시 회전, 요청 최적화로 차단 위험 최소화
장시간, 동시처리 환경에서도 일관된 크롤 성능 제공
명확한 문서 기반 심플 API로 신속하게 세팅/제어
분석, 데이터웨어하우스, AI에 바로 활용 가능한 구조화 크롤 데이터
XCrawl을 사용하는 개발자들과 함께 구조화된 웹 데이터로 AI 애플리케이션을 강화하세요. 지금 1,000 크레딧 무료로 시작할 수 있습니다.






XCrawl에 대해 꼭 알아야 할 모든 것.



