クロールAPIとは?
クロールAPIにより、開発者とデータチームはWebサイト全体または大規模なURLセットをプログラムでクロールできます。
クロールロジック、リクエストスケジューリング、アンチボット保護を管理し、インフラストラクチャではなくデータ抽出に集中できます。
当社のクロールAPIは、HTML抽出API、生ページスクレーパー、ヘッドレスブラウザAPIを統合されたWebクローラーインターフェースに統合します。大規模で定期的なWebデータ収集向けに設計されたこのクロールAPIにより、クロールルールを一度定義すれば、数千または数百万のページにわたって構造化データを自動的に収集できます。
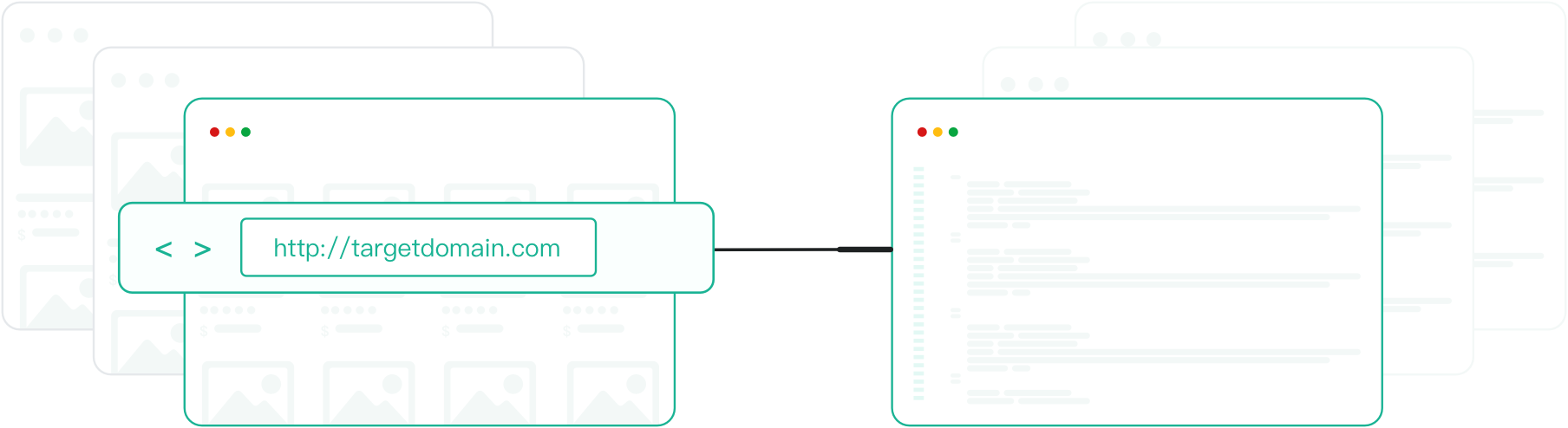
クロールAPIにより、開発者とデータチームはWebサイト全体または大規模なURLセットをプログラムでクロールできます。
クロールロジック、リクエストスケジューリング、アンチボット保護を管理し、インフラストラクチャではなくデータ抽出に集中できます。
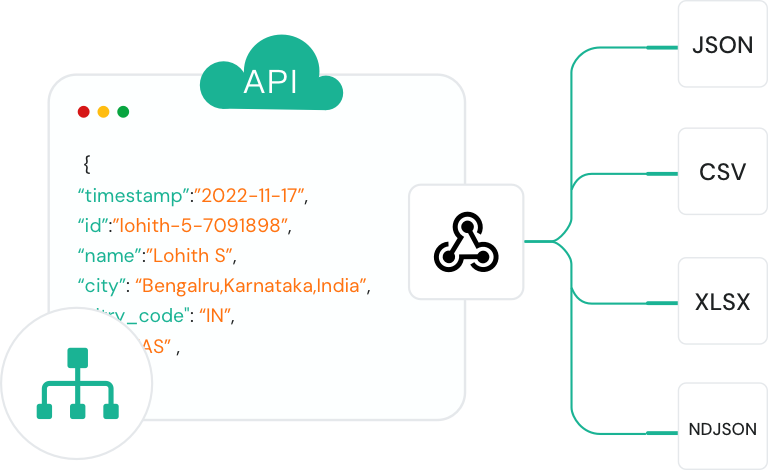
Web全体で大規模なデータ収集を自動化
クロールAPIにより、チームはWebサイト全体で大量の公開Webデータを収集できます。製品カタログ、記事アーカイブ、ディレクトリスタイルのコンテンツなど、完全なサイトカバレッジを必要とするデータセットの構築に最適です。
競合他社のWebサイトを継続的にクロールすることで、企業は価格変更、コンテンツ更新、製品発売を時間の経過とともに監視できます。クロールAPIにより、トレンドを検出し、市場の動きに迅速に対応することが容易になります。
クロールAPIは、SEOチームがサイト構造、内部リンク、メタデータ、インデックス可能性を大規模に分析するのに役立ちます。大量のページをクロールすることで、チームは技術的な問題を特定し、サイトパフォーマンスをより効果的に最適化できます。
クロールAPIは、AIおよび機械学習ワークフロー向けの長期的なデータ収集をサポートします。クロールされたデータは保存され、スケジュールに従って更新され、モデルのトレーニング、ナレッジベース、または大規模分析に使用できます。
わずか数行のコードで簡単抽出!

透明なWebスクレイピング価格設定と柔軟なAPIサブスクリプションプラン。データ抽出コストを比較し、クローラーアクセスを購入して無料で開始 — その後、成長に応じて拡張。
より高いパワーと専任サポートが必要なチーム向け大規模プラン。
より高いレート制限・同時実行数・優先サポートが利用可能です。

数千から数百万のページを効率的かつ確実にクロールするように設計されています。
API経由でクロール範囲、深度、スケジューリングをきめ細かく制御できます。
組み込みのプロキシローテーションとリクエスト最適化により、ブロックや禁止を回避します。
高い同時実行性と長時間実行ジョブでも一貫したクロールパフォーマンスを実現します。
明確なドキュメントを備えたシンプルなAPI設計により、迅速なセットアップと制御が可能です。
分析、データウェアハウス、AIワークフローに適した構造化クロールデータ。
構造化されたWebデータでAIアプリを構築する開発者たちと一緒に、XCrawlを活用しましょう。1,000無料クレジットから始められます。






XCrawlについて知っておくべきすべて。



