Ingestion de sites clients en quelques minutes au lieu de mois
Le Smart Crawler de XCrawl fournit des AI Training Data via LLM Web Scraping, extrayant des Customer Support Data avec notre FAQ Scraper et nos outils de Knowledge Base Extraction. Notre Help Center Crawler et nos capacités de Support Ticket Data transforment des sites web désordonnés en Machine Learning Datasets propres qui offrent un AI Agent Context parfait pour vos chatbots de service client et systèmes RAG.
Les APIs de scraping génériques échouent sur les sites complexes
Les outils de collecte de données d’XCrawl extraient des informations de sites web difficiles à scraper et renvoient des données propres et utilisables dans un format cohérent. Inutile de trouver des points de terminaison API personnalisés, la structure HTML ou faire des requêtes GraphQL. Obtenez juste la donnée.
Obtenez des données à jour sur tout site web
XCrawl récupère des données de tout type de source web, utilisables directement pour vos agents IA.
Utilisez des scrapers créés par des développeurs expérimentés
Choisissez parmi des milliers d’outils de scraping prêts à l’emploi, testés et utilisés par des clients payants.
Alimentez vos agents avec des données exploitables
XCrawl renvoie des données structurées et pertinentes adaptées à chaque site, pour que les agents puissent les traiter et agir sans analyse ou interprétation supplémentaires.
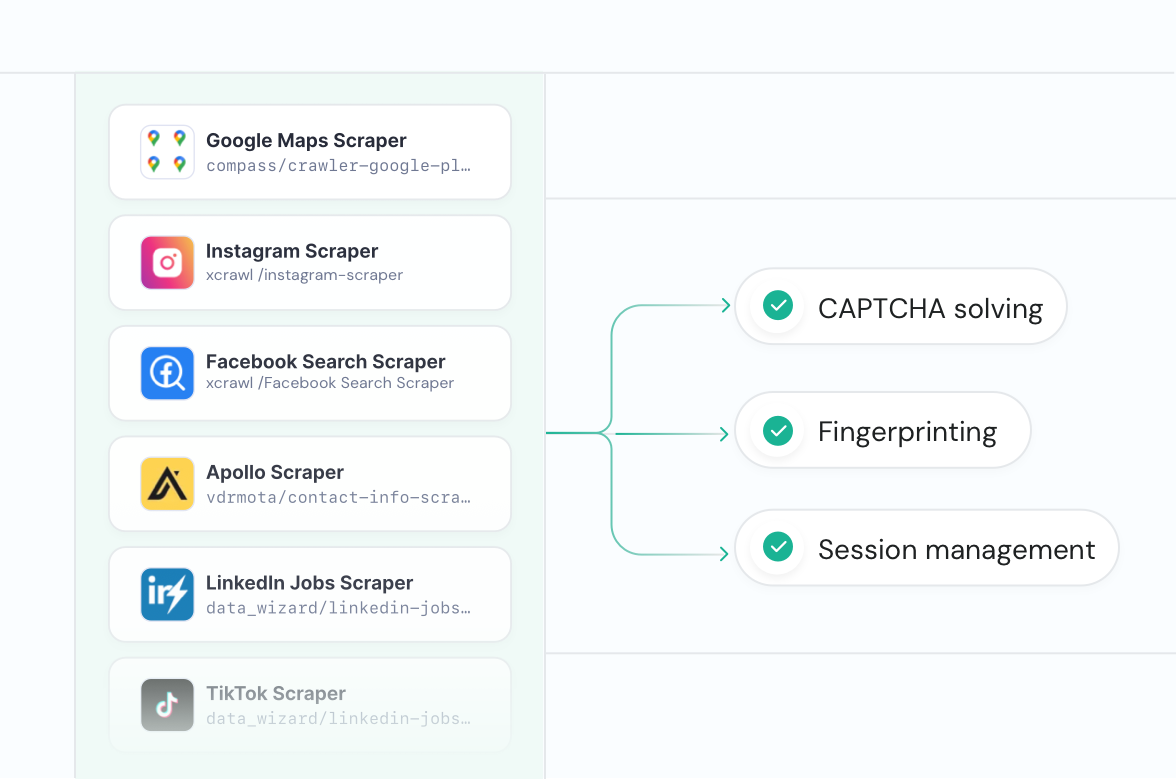
Aucune donnée n’est hors de portée
Les solutions de scraping traditionnelles sont limitées aux sites web simples uniquement. XCrawl fournit des outils qui gèrent la résolution de CAPTCHA, l'empreinte digitale et la gestion de session prêts à l'emploi pour accéder même aux sites web les plus complexes. Utilisez les scrapers que les développeurs ont créés et publiés sur XCrawl Store pour obtenir des données de n'importe quel site web pour vos agents.
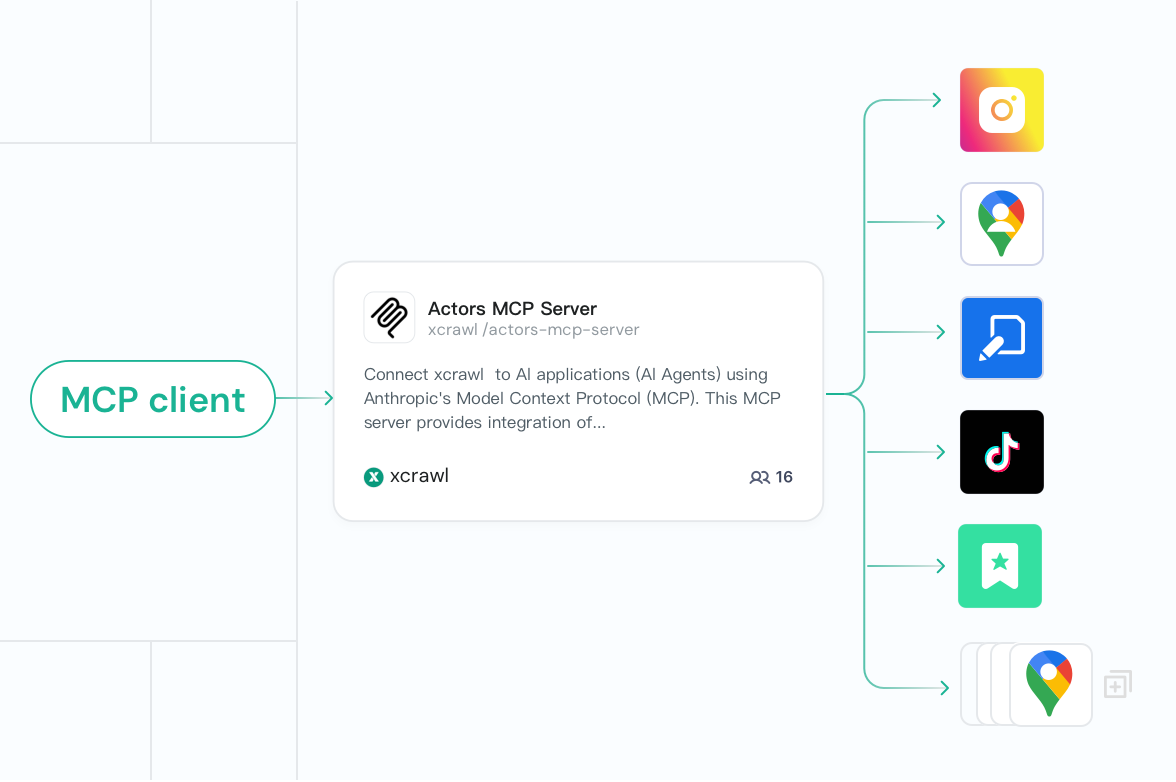
Connectez les agents aux outils XCrawl via MCP
Le serveur MCP d’XCrawl permet aux agents de trouver, lancer et récupérer des données de l’outil adéquat automatiquement. Les agents fonctionnent de manière autonome : ils extraient des données en direct, réagissent aux changements du monde réel et accomplissent des tâches sans sollicitation manuelle.
Comment fonctionne l’API de scraping ?
Étape 1 : Initiez une requête API et transmettez les informations de la page web à traiter via une URL simple.
Étape 2 : Le serveur traite les données de la page et renvoie des données structurées (telles que JSON, CSV, etc.).
Étape 3 : Analysez les données, obtenez les informations requises, puis effectuez les analyses ou présentations nécessaires.
Pourquoi XCrawl ?
Accès fiable à grande échelle
Chaque forfait (y compris le forfait gratuit) est livré avec XCrawl Proxy, conçu pour aider à réduire les échecs de requêtes et prendre en charge l'accès au contenu géo-spécifique.
Les clients nous adorent
Nous nous soucions vraiment de la satisfaction de nos utilisateurs et grâce à cela, nous sommes l'une des plateformes d'extraction de données les mieux notées sur G2 et Capterra.
Surveillez vos exécutions
Avec nos dernières fonctionnalités de surveillance, vous avez toujours un accès immédiat à des insights précieux sur l'état de vos tâches de web scraping.
Exportez vers divers formats
Vos ensembles de données peuvent être exportés vers n'importe quel format adapté à votre workflow de données, y compris Excel, CSV, JSON, XML, tableau HTML, JSONL et RSS.
Intégrez XCrawl à votre workflow
Vous pouvez intégrer vos exécutions XCrawl avec des plateformes telles que Zapier, Make, Keboola, Google Drive ou GitHub. Connectez-vous à pratiquement n'importe quel service cloud ou application web.
Conçu pour les développeurs
XCrawl est développé par une équipe d'ingénierie expérimentée, avec un support technique continu disponible via notre communauté Discord.
Accès fiable à grande échelle
Chaque forfait (y compris le forfait gratuit) est livré avec XCrawl Proxy, conçu pour aider à réduire les échecs de requêtes et prendre en charge l'accès au contenu géo-spécifique.
Les clients nous adorent
Nous nous soucions vraiment de la satisfaction de nos utilisateurs et grâce à cela, nous sommes l'une des plateformes d'extraction de données les mieux notées sur G2 et Capterra.
Surveillez vos exécutions
Avec nos dernières fonctionnalités de surveillance, vous avez toujours un accès immédiat à des insights précieux sur l'état de vos tâches de web scraping.
Exportez vers divers formats
Vos ensembles de données peuvent être exportés vers n'importe quel format adapté à votre workflow de données, y compris Excel, CSV, JSON, XML, tableau HTML, JSONL et RSS.
Intégrez XCrawl à votre workflow
Vous pouvez intégrer vos exécutions XCrawl avec des plateformes telles que Zapier, Make, Keboola, Google Drive ou GitHub. Connectez-vous à pratiquement n'importe quel service cloud ou application web.
Conçu pour les développeurs
XCrawl est développé par une équipe d'ingénierie expérimentée, avec un support technique continu disponible via notre communauté Discord.
Questions fréquentes
Tout ce que vous devez savoir sur XCrawl.
Qu'est-ce que XCrawl ?
XCrawl est une API de web scraping prête pour l’IA qui convertit les sites web en JSON structuré, Markdown, HTML et captures d’écran. Elle inclut des proxies intégrés, le crawling et des données SERP pour les développeurs.
En quoi XCrawl est-il différent des autres outils de web scraping ?
Les scrapers traditionnels renvoient souvent du HTML brut. XCrawl fournit un JSON et un Markdown propres, une rotation automatique des proxies intégrée, une API SERP et des intégrations avec MCP, n8n et Zapier pour accélérer les workflows de production.
XCrawl est-il gratuit à l’essai ?
Oui. Chaque nouveau compte comprend 1 000 crédits gratuits sans carte bancaire requise, afin que vous puissiez tester le scraping, le crawling, les données SERP et les résultats prêts pour l’IA avant de passer à une offre supérieure.
XCrawl peut-il scraper des sites web très dynamiques en JavaScript ?
Oui. XCrawl utilise un rendu navigateur headless pour gérer les SPAs, le scroll infini et les contenus dynamiques côté client, puis extrait les données une fois les éléments clés chargés.
Quels formats de sortie XCrawl gère-t-il ?
XCrawl retourne du JSON structuré, du Markdown prêt pour l’IA, du HTML brut et des captures d’écran. Utilisez le JSON pour l’intégration dans vos systèmes et le Markdown pour des workflows LLM plus efficaces.
Avec quels langages de programmation peut-on utiliser XCrawl ?
XCrawl est une API REST, donc elle fonctionne avec n’importe quel langage. Des SDK officiels existent pour Python et Node.js/TypeScript, avec des exemples pour Go, Ruby, PHP et cURL.
XCrawl fonctionne-t-il avec des agents IA et des outils d’automatisation ?
Oui. XCrawl prend en charge MCP pour Claude, ainsi que n8n, Zapier, Make et des pipelines personnalisés pour permettre aux agents IA d’accéder aux données web en direct en temps réel.
Comment démarrer avec XCrawl ?
Créez un compte gratuit sur xcrawl.com, copiez votre clé API depuis le tableau de bord et envoyez votre première requête. Vous recevez 1 000 crédits gratuits et des exemples de démarrage pour Python, Node.js et cURL.
Comment fonctionnent la tarification et les crédits XCrawl ?
Chaque requête utilise des crédits en fonction de sa complexité. Les pages standard, les requêtes SERP et les fonctionnalités avancées peuvent consommer des montants différents. Consultez la page de tarification pour le dernier tableau des crédits.
Ai-je besoin de compétences en programmation pour utiliser XCrawl ?
Non. Vous pouvez utiliser XCrawl via des plateformes no-code comme n8n et Zapier ou utiliser des SDK et appels REST pour des workflows avancés destinés aux développeurs.
Commencez à scraper plus intelligemment dès aujourd’hui !
Accédez à des données web fiables et prêtes à l’emploi depuis les plus grands sites, à grande échelle — des pipelines automatisés éliminent le travail manuel et accélèrent le passage aux insights.