Skalierungs-Tarife
High-Volume-Tarife für Teams mit hohem Bedarf und dediziertem Support.
Profitieren Sie von höheren Raten, mehr gleichzeitigen Browsern und Prioritätssupport.
Unsere YouTube Scraper API extrahiert umfassende YouTube-Kommentardaten durch Video Metadata Extraction und YouTube Transcript API – von IDs und Inhalten bis hin zu Engagement-Kennzahlen, Channel Stats Scraper und Video Trends Data – mit voller Prozesskontrolle, reibungsloser Skalierung und zuverlässiger High-Performance.
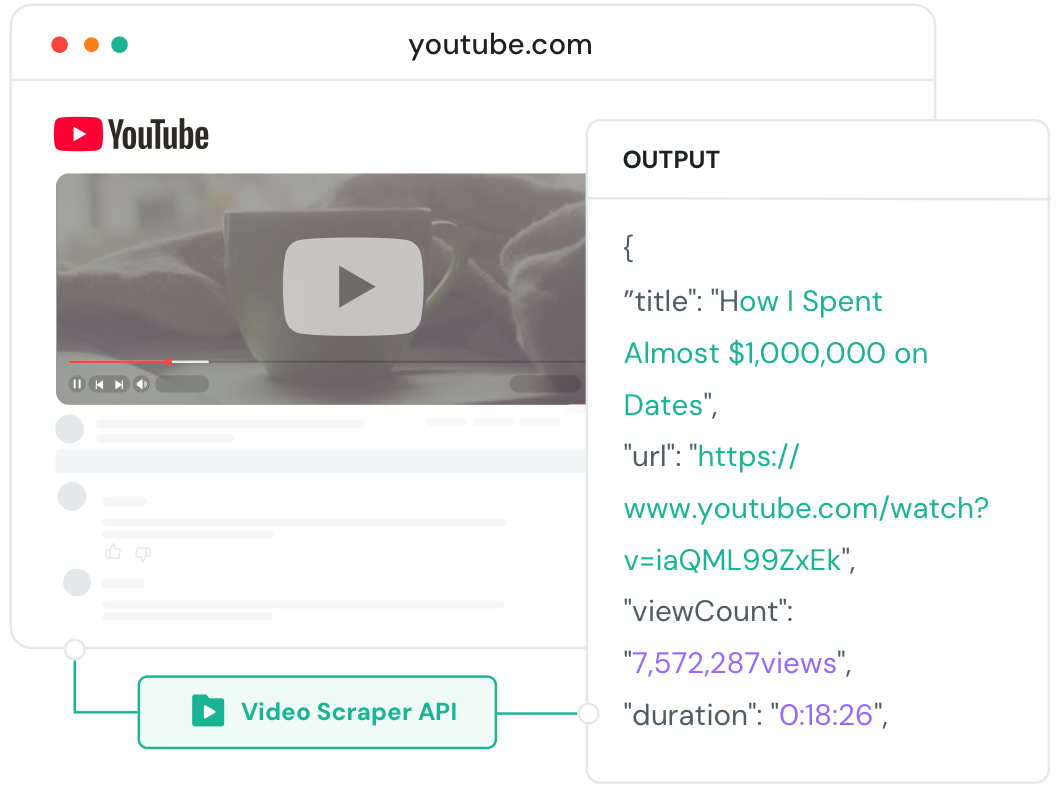
Keine Ratenlimits, Sperren oder yt-dlp-Fehler mehr. Einfach stabile, Petabyte-große Videodatenerfassung für AI-Training.
Video- & Audiodownload | Texte & Untertitel | Komplette Videokommentare | Video-Metadaten |
Video- & Audiodownload |
Texte & Untertitel |
Komplette Videokommentare |
Video-Metadaten |
Nur wenige simple Schritte für klar strukturierte YouTube-Daten.
01Videos finden und bewerten STEP1.1 Videoquellen direkt mit der Video-ID oder -URL abrufen und analysieren | 02Videos und Untertitel herunterladen STEP2.1 Video-/Audio-Inhalte herunterladenSTEP2.2 Videotranskripte abrufen | 03Cloud-Sync & Export STEP3.1 Lädt Daten automatisch in den von Ihnen angegebenen CloudspeicherSTEP3.2 Erzeugt teilbare Links und stellt API-Zugänge bereit |
01Videos finden und bewerten STEP1.1 Videoquellen direkt mit der Video-ID oder -URL abrufen und analysieren |
02Videos und Untertitel herunterladen STEP2.1 Video-/Audio-Inhalte herunterladenSTEP2.2 Videotranskripte abrufen |
03Cloud-Sync & Export STEP3.1 Lädt Daten automatisch in den von Ihnen angegebenen CloudspeicherSTEP3.2 Erzeugt teilbare Links und stellt API-Zugänge bereit |
Transparente Web-Scraping-Preise mit flexiblen API-Abonnement-Plänen. Vergleichen Sie Datenextraktionskosten, kaufen Sie Crawler-Zugang und starten Sie kostenlos — dann skalieren Sie nach Bedarf.
High-Volume-Tarife für Teams mit hohem Bedarf und dediziertem Support.
Profitieren Sie von höheren Raten, mehr gleichzeitigen Browsern und Prioritätssupport.

Proxy-ManagementML-basierte Proxy-Auswahl und -Rotation – mit unserem Premium-Proxy-Pool aus 190 Ländern. | KI-gesteuertes FingerprintingEinzigartige HTTP-Header, JavaScript- und Browser-Fingerprints sorgen für Widerstandsfähigkeit gegenüber dynamischen Inhalten. | CAPTCHA-UmgehungAutomatische Wiederholung und CAPTCHA-Umgehung für eine unterbrechungsfreie Datengewinnung. |
MassendatenextraktionExtrahieren Sie gleichzeitig Daten von mehreren Seiten – mit bis zu 10.000 URLs pro Stapel. | Mehrere BereitstellungsoptionenEmpfangen Sie Daten über Cloudspeicher wie SFTP oder AWSS3 oder rufen Sie Ergebnisse per API ab. | Geplantes ScrapingStellen Sie die gewünschte Frequenz für automatisierte, zeitgesteuerte Datenerhebung ein. Ergebnisse werden direkt an Ihren Cloud-Speicher geliefert. |
Wartungsfreie InfrastrukturVermeiden Sie Proxy-Wartung und Infrastrukturaufwand. Kein Aufbau eines eigenen Crawler-Systems nötig. | Hochgradig skalierbarEinfache Integration, Anpassungsmöglichkeiten inklusive. | 24/7 SupportErhalten Sie professionellen Support bei Fragen oder Problemen. |
Proxy-ManagementML-basierte Proxy-Auswahl und -Rotation – mit unserem Premium-Proxy-Pool aus 190 Ländern. |
KI-gesteuertes FingerprintingEinzigartige HTTP-Header, JavaScript- und Browser-Fingerprints sorgen für Widerstandsfähigkeit gegenüber dynamischen Inhalten. |
CAPTCHA-UmgehungAutomatische Wiederholung und CAPTCHA-Umgehung für eine unterbrechungsfreie Datengewinnung. |
LLM-bereite Daten erhalten
Wir liefern strukturierte, KI-fähige Daten. YouTube-Videos, Transkripte, Untertitel, Metadaten und Suchergebnisse sind sofort integrierbar in LLMs, KI-Modelle und Analyseworkflows.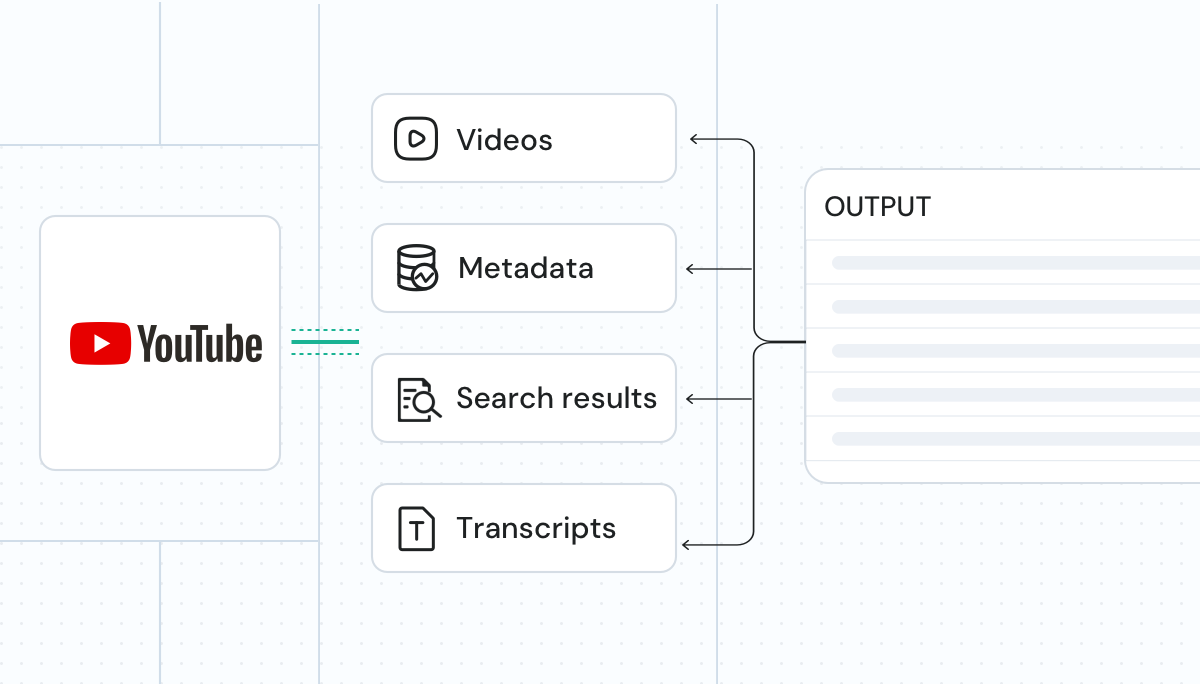
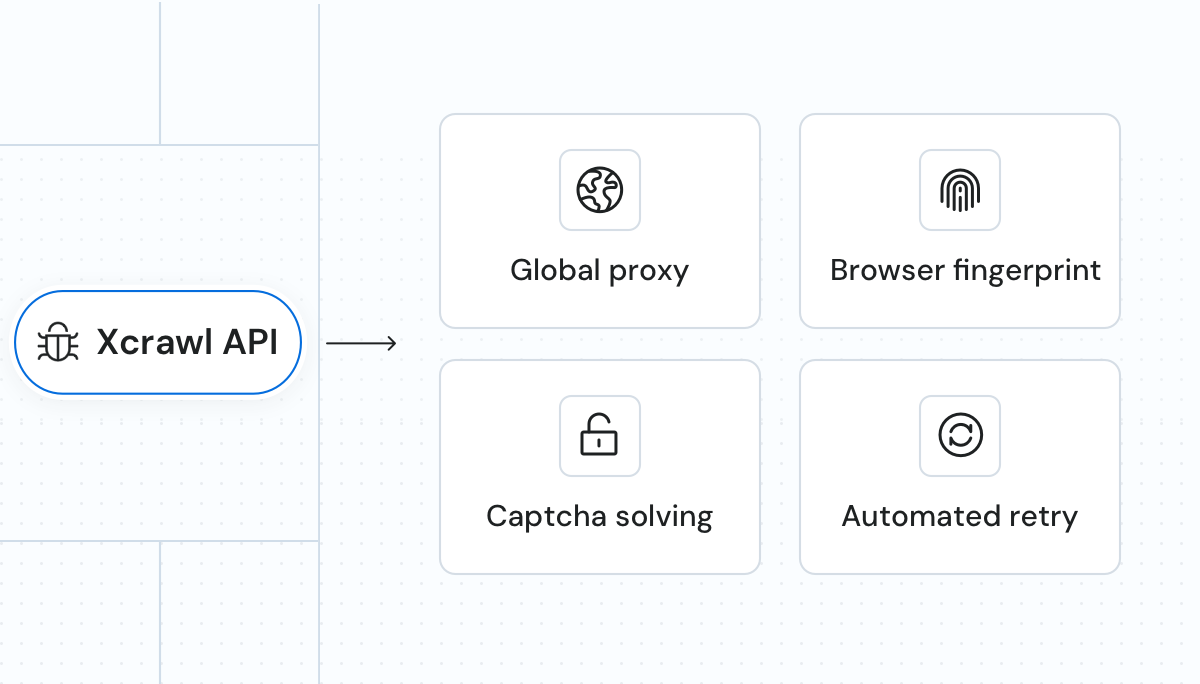
Datenservices. Kein Wartungsaufwand.
Greifen Sie weltweit auf hochwertige Videodaten aus echtem Webtraffic zuAlles, was Sie über XCrawl wissen müssen.



