Bauen Sie Ihre Anfrage mit unserer API
Großflächiges Webscraping via API, unterstützt 9 Programmiersprachen.
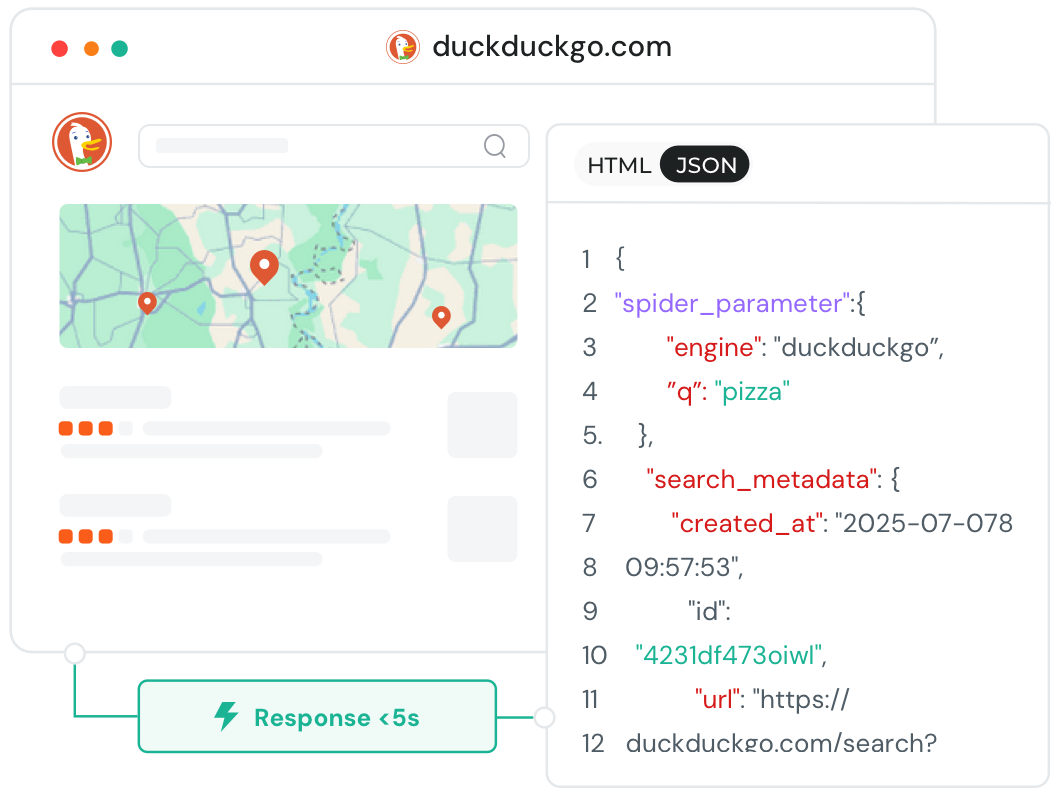
Nutzen Sie unseren DuckDuckGo Scraper und DDG API für großflächige, stabile und zuverlässige Erhebung von Privacy Search Data durch Anonymous Search Scraping. Extrahieren Sie präzise Echtzeitdaten mit DuckDuckGo SERP Funktionen für Marktbeobachtung, SEO und mehr.
Daten sind der Treibstoff für KI – und das Web ist die größte Datenquelle überhaupt. Die heutigen Sprachmodelle wie ChatGPT oder LLaMA wurden alle mit gescrapten Webdaten trainiert. XCrawl verschafft Ihnen dieselben Superkräfte und bringt riesige Webdaten direkt zu Ihnen.
Verfolgen Sie neue Inhalte, Schlagworte und Diskussionen, sobald sie auf DuckDuckGo erscheinen.
Sammeln Sie große Mengen strukturierter Daten für Analyse, Reporting und Insights.
Überwachen Sie Mitbewerber und öffentliche Akteure – ganz ohne manuellen Aufwand.
Speisen Sie saubere, zuverlässige Daten in Dashboards, Modelle oder interne Systeme ein.

Greifen Sie auf die meistgenutzten DuckDuckGo Datentypen zu – vollständig strukturiert, einheitlich formatiert und produktionsbereit.
DuckDuckGo-Post-ScraperAutorname, Autor-ID, Verifizierungsstatus, URL-ID, Post-Inhalt, Kommentare, Antworten, Likes, Shares, Video-URL, Bild-URL, Veröffentlichungsdatum usw.Scraping-Methode: Suchbegriff Neueste Beiträge Jahr Anzahl der Elemente | DuckDuckGo-Profil-ScraperAutorname, Autor-ID, Profil-URL, Avatar, Verifizierungsstatus, URL-ID usw.Scraping-Methode: URL | DuckDuckGo-Reels-ScraperURL, Post-ID, Benutzer-URL, Original-Benutzername, Inhalt, Veröffentlichungsdatum, Tags, Anzahl der Kommentare usw.Scraping-Methode: URL |
DuckDuckGo-Kommentar-ScraperURL, Post-ID, Post-URL, Kommentar-ID, Benutzername, Benutzer-ID, Benutzer-URL, Erstellungsdatum usw.Scraping-Methode: URL | DuckDuckGo-Firmenbewertungs-ScraperFirmenname, Firmen-ID, Firmen-URL, URL, Bewertungsdatum, Empfehlung, Bewertungsinhalt, Anhänge usw.Scraping-Methode: URL | Brauchen Sie mehr DuckDuckGo-Scraping-Tools?Kontaktieren Sie unsere Fachexperten für eine individuelle Daten-Scraping-Lösung. |
DuckDuckGo-Post-ScraperAutorname, Autor-ID, Verifizierungsstatus, URL-ID, Post-Inhalt, Kommentare, Antworten, Likes, Shares, Video-URL, Bild-URL, Veröffentlichungsdatum usw.Scraping-Methode: Suchbegriff Neueste Beiträge Jahr Anzahl der Elemente |
DuckDuckGo-Profil-ScraperAutorname, Autor-ID, Profil-URL, Avatar, Verifizierungsstatus, URL-ID usw.Scraping-Methode: URL |
DuckDuckGo-Reels-ScraperURL, Post-ID, Benutzer-URL, Original-Benutzername, Inhalt, Veröffentlichungsdatum, Tags, Anzahl der Kommentare usw.Scraping-Methode: URL |
DuckDuckGo-Kommentar-ScraperURL, Post-ID, Post-URL, Kommentar-ID, Benutzername, Benutzer-ID, Benutzer-URL, Erstellungsdatum usw.Scraping-Methode: URL |
DuckDuckGo-Firmenbewertungs-ScraperFirmenname, Firmen-ID, Firmen-URL, URL, Bewertungsdatum, Empfehlung, Bewertungsinhalt, Anhänge usw.Scraping-Methode: URL |
Brauchen Sie mehr DuckDuckGo-Scraping-Tools?Kontaktieren Sie unsere Fachexperten für eine individuelle Daten-Scraping-Lösung. |
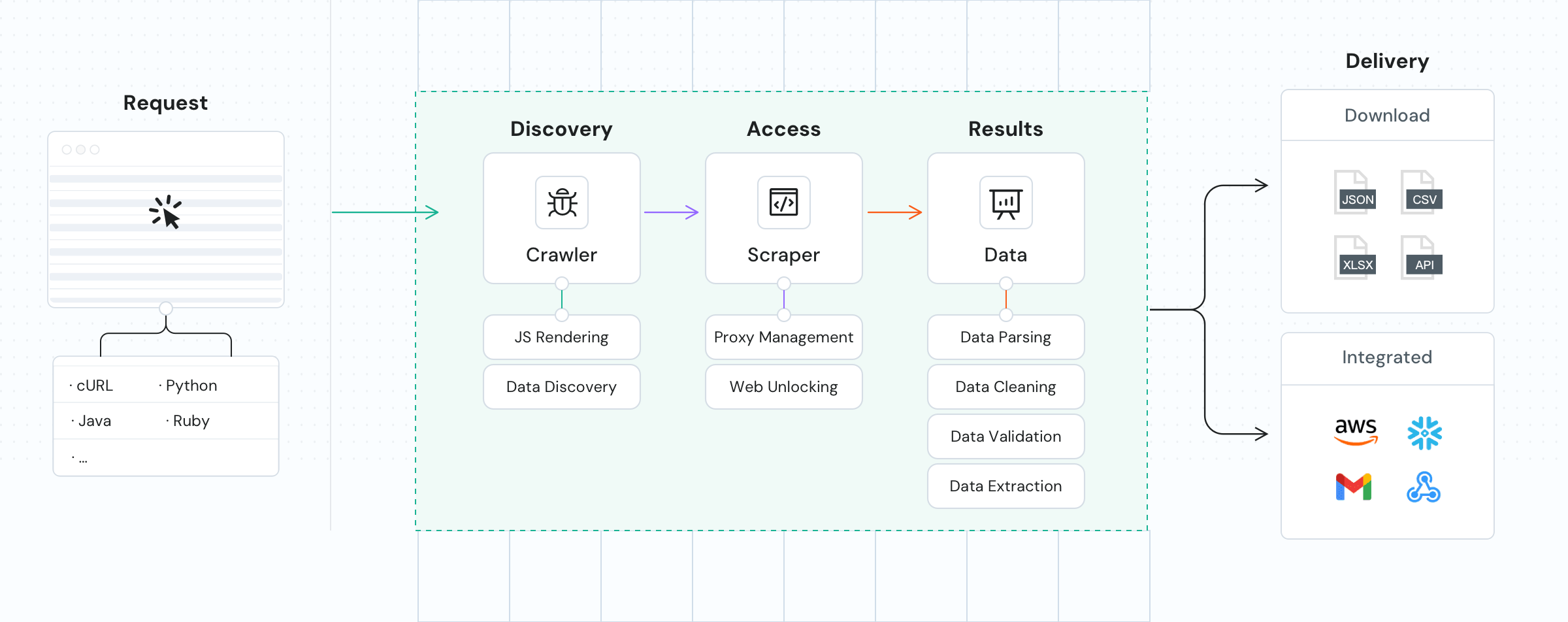
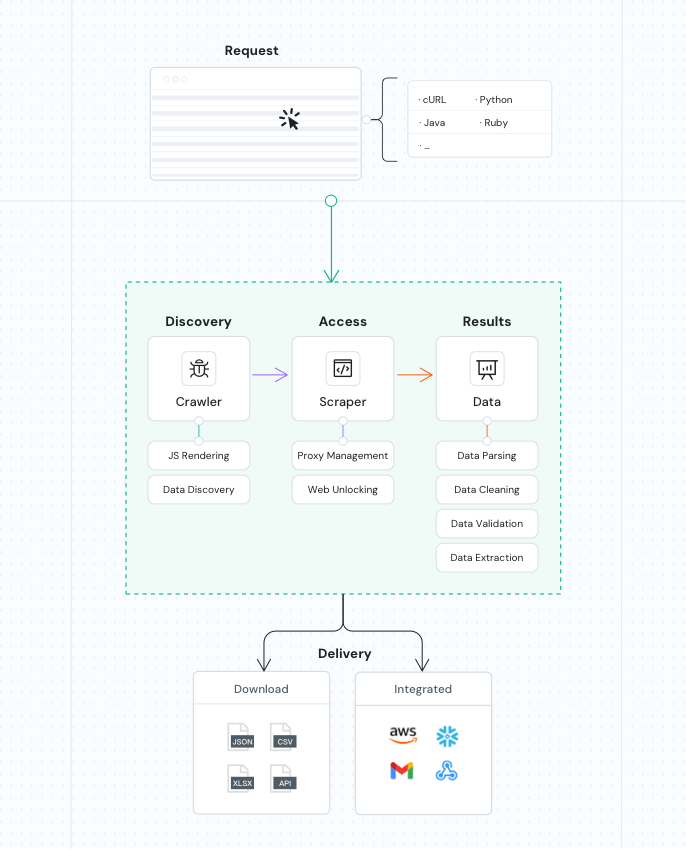
Starten Sie die API, um bestimmte Daten von zu scrapen.
Scrapen Sie ausgewählte Daten von direkt im Dashboard.
ML-basierte Proxy-Auswahl und -Rotation – mit unserem Premium-Proxy-Pool aus 190 Ländern.
Einzigartige HTTP-Header, JavaScript- und Browser-Fingerprints sorgen für Widerstandsfähigkeit gegenüber dynamischen Inhalten.
Automatische Wiederholung und CAPTCHA-Umgehung für eine unterbrechungsfreie Datengewinnung.
Extrahieren Sie Daten gleichzeitig von mehreren Seiten – mit bis zu 10.000 URLs pro Durchgang.
Empfangen Sie Daten über Cloudspeicher wie SFTP oder AWSS3 oder rufen Sie Ergebnisse per API ab.
Stellen Sie die gewünschte Frequenz für automatisierte, zeitgesteuerte Datenerhebung ein. Ergebnisse werden direkt an Ihren Cloud-Speicher geliefert.
Vermeiden Sie Proxy-Wartung und Infrastrukturaufwand. Sie müssen kein eigenes Crawling-System bauen.
Leicht integrierbar und anpassbar.
Erhalten Sie professionellen Support bei Fragen oder Problemen.
Transparente Web-Scraping-Preise mit flexiblen API-Abonnement-Plänen. Vergleichen Sie Datenextraktionskosten, kaufen Sie Crawler-Zugang und starten Sie kostenlos — dann skalieren Sie nach Bedarf.
High-Volume-Tarife für Teams mit hohem Bedarf und dediziertem Support.
Profitieren Sie von höheren Raten, mehr gleichzeitigen Browsern und Prioritätssupport.

Unsere Google Scraper API unterstützt effizientes Crawling und großflächigen Zugriff auf Google Search Results in Echtzeit durch SERP Data Extraction – mit Abdeckung für organische Suche, Anzeigen, Videos, Bilder und Karten. Angetrieben von Google Trends API und Search Engine Crawler Technologie.
Mehr erfahrenNutzen Sie unsere Amazon Scraper API, um Amazon Product Data abzurufen, einschließlich Produktauflistungen, globale Produktdetails, Kundenbewertungen und Verkäuferinformationen. Unser ASIN Scraper und Amazon Reviews API extrahieren über 500 Felder von Amazon in Echtzeit mit E-commerce Extraction Funktionen.
Mehr erfahrenUnsere YouTube Scraper API extrahiert umfassende YouTube-Kommentardaten durch Video Metadata Extraction und YouTube Transcript API – von IDs und Inhalten bis hin zu Engagement-Kennzahlen, Channel Stats Scraper und Video Trends Data – mit voller Prozesskontrolle, reibungsloser Skalierung und zuverlässiger High-Performance.
Mehr erfahrenUnsere Instagram Scraper API ruft Echtzeit IG Profile Data von Instagram ab – Instagram Post Scraper für Posts, Profile, Kommentare, Reels, Social Media Images und über 200 Felder. Perfekt für Influencer Tracking und Social-Media-Analysen.
Mehr erfahrenNutzen Sie unsere Facebook Scraper API, um Echtzeitdaten von Social Media Data zu erhalten. Unser FB Page Extractor und Public Post Scraper ermöglichen Social Listening durch Extraktion von Posts, Profilen, Kommentaren, Reels, Unternehmensbewertungen und über 100 weiteren Feldern.
Mehr erfahrenUnsere Walmart Scraper API bietet Zugriff auf Echtzeit Walmart Product Data (über 120 Felder) durch unseren Retail Price Scraper und E-commerce Scraper – IDs, Namen, Preise, Rabatte, Kategorien, Marken, Bilder, Daten, Bewertungen, Bestseller. Angetrieben von Walmart Inventory API Technologie mit smarter CAPTCHA- und IP-Block-Umgehung.
Mehr erfahrenDie Web Scraper API von XCrawl war besser als jedes Tool, das wir vorher genutzt haben. Die Echtzeitdaten und der Anti-Bot-Schutz sind herausragend.
Unsere KI-Agenten verlassen sich auf XCrawl für SERP-API und großflächiges Scraping. Die Integration war extrem einfach.
Die Anti-Bot-Umgehung ist die beste, die wir getestet haben. Schwierige Websites sind kein Problem mehr.
Perfekt für KI-Workflows, die Echtzeit-Webdaten erfordern. Die JSON-Ausgabe ist immer sauber.
Großartige Unterstützung beim Scraping sozialer Medien. Wir extrahieren Posts und Metriken problemlos im großen Stil.
Zuverlässig für Preisüberwachung und Wettbewerbsanalyse. Die Web Scraper API ist absolut stabil.
CAPTCHA-lastige Websites haben uns früher gestoppt, aber XCrawl meistert sie ohne manuelle Eingriffe.
Das universelle Scraping-Endpunkt spart uns sehr viel Entwicklungszeit. Eine API für alles.
Wir versorgen unsere Agenten mit Echtzeit-Webdaten über XCrawl. Das verbesserte die Entscheidungsgenauigkeit erheblich.
Die SERP-API ist schnell und präzise – perfekt für Keyword-Tracking und SEO.
JavaScript-lastige Seiten laden perfekt. Viel besser als unser altes Puppeteer-Setup.
Wir lieben die eingebauten Pipelines. Das Senden der Ergebnisse zu S3 und GCS ist nahtlos.
Unsere Automationsbots nutzen XCrawl, um zuverlässige Social-Media-Daten plattformübergreifend zu sammeln.
Wir haben mehrere Inhouse-Scraper durch XCrawl ersetzt. Wartungsaufwand fast null.
Ideal für strukturierte Datenextraktion. Funktioniert für E-Commerce, News, Blogs – alles.
Unser Team war dank der klaren API und Dokumentation sofort produktiv.
Echtzeitscraping hat die Performance unserer Prognosemodelle signifikant verbessert.
Selbst bei hoher Auslastung bleibt die API stabil und schnell. Sehr beeindruckend.
Die Web Scraper API von XCrawl war besser als jedes Tool, das wir vorher genutzt haben. Die Echtzeitdaten und der Anti-Bot-Schutz sind herausragend.
Unsere KI-Agenten verlassen sich auf XCrawl für SERP-API und großflächiges Scraping. Die Integration war extrem einfach.
Die Anti-Bot-Umgehung ist die beste, die wir getestet haben. Schwierige Websites sind kein Problem mehr.
Perfekt für KI-Workflows, die Echtzeit-Webdaten erfordern. Die JSON-Ausgabe ist immer sauber.
Großartige Unterstützung beim Scraping sozialer Medien. Wir extrahieren Posts und Metriken problemlos im großen Stil.
Zuverlässig für Preisüberwachung und Wettbewerbsanalyse. Die Web Scraper API ist absolut stabil.
CAPTCHA-lastige Websites haben uns früher gestoppt, aber XCrawl meistert sie ohne manuelle Eingriffe.
Das universelle Scraping-Endpunkt spart uns sehr viel Entwicklungszeit. Eine API für alles.
Wir versorgen unsere Agenten mit Echtzeit-Webdaten über XCrawl. Das verbesserte die Entscheidungsgenauigkeit erheblich.
Die SERP-API ist schnell und präzise – perfekt für Keyword-Tracking und SEO.
JavaScript-lastige Seiten laden perfekt. Viel besser als unser altes Puppeteer-Setup.
Wir lieben die eingebauten Pipelines. Das Senden der Ergebnisse zu S3 und GCS ist nahtlos.
Unsere Automationsbots nutzen XCrawl, um zuverlässige Social-Media-Daten plattformübergreifend zu sammeln.
Wir haben mehrere Inhouse-Scraper durch XCrawl ersetzt. Wartungsaufwand fast null.
Ideal für strukturierte Datenextraktion. Funktioniert für E-Commerce, News, Blogs – alles.
Unser Team war dank der klaren API und Dokumentation sofort produktiv.
Echtzeitscraping hat die Performance unserer Prognosemodelle signifikant verbessert.
Die SERP-API liefert exakte Rankings und Rich Snippets. Super für SEO-Teams.
Die Echtzeit-Extraktion hat unsere LLM-Fine-Tuning-Datensätze enorm verbessert.
Universelle Scraping-Unterstützung – kein Bedarf mehr an eigenen Spidern. Riesige Zeitersparnis.
Wir verfolgen täglich Tausende Seiten mit XCrawl. Die API ist absolut zuverlässig.
Webhook-Lieferung und Cloud-Pipeline-Support machen die Automatisierung einfacher.
Unsere LLM-Agenten nutzen XCrawl für Echtzeit-Reasoning-Aufgaben. Fantastischer Service.
XCrawl hat teure Enterprise-Scraping-Tools zu einem Bruchteil der Kosten ersetzt.
Die API liefert immer strukturierte und saubere Daten. Tolle Konsistenz.
n8n-Integration funktioniert perfekt. Unsere Datenflüsse laufen jetzt automatisch.
Die Schnelligkeit der XCrawl-Scraping-API ist unübertroffen. Perfekt für hochfrequentes Crawlen.
Wir sammeln Wettbewerber-Content in Echtzeit – das hilft unserer Strategie enorm.
E-Commerce-Seiten werden fehlerlos gescrapet. Besser als unser Headless-Browser-Setup.
Unsere Workflows laufen seit dem Wechsel zu XCrawl deutlich reibungsloser.
Strukturierte Ausgabe spart uns jede Woche Stunden an Nachbearbeitung.
Die SERP-API liefert exakte Rankings und Rich Snippets. Super für SEO-Teams.
Die Echtzeit-Extraktion hat unsere LLM-Fine-Tuning-Datensätze enorm verbessert.
Universelle Scraping-Unterstützung – kein Bedarf mehr an eigenen Spidern. Riesige Zeitersparnis.
Wir verfolgen täglich Tausende Seiten mit XCrawl. Die API ist absolut zuverlässig.
Webhook-Lieferung und Cloud-Pipeline-Support machen die Automatisierung einfacher.
Unsere LLM-Agenten nutzen XCrawl für Echtzeit-Reasoning-Aufgaben. Fantastischer Service.
XCrawl hat teure Enterprise-Scraping-Tools zu einem Bruchteil der Kosten ersetzt.
Die API liefert immer strukturierte und saubere Daten. Tolle Konsistenz.
n8n-Integration funktioniert perfekt. Unsere Datenflüsse laufen jetzt automatisch.
Die Schnelligkeit der XCrawl-Scraping-API ist unübertroffen. Perfekt für hochfrequentes Crawlen.
Wir sammeln Wettbewerber-Content in Echtzeit – das hilft unserer Strategie enorm.
E-Commerce-Seiten werden fehlerlos gescrapet. Besser als unser Headless-Browser-Setup.
Unsere Workflows laufen seit dem Wechsel zu XCrawl deutlich reibungsloser.






Alles, was Sie über XCrawl wissen müssen.



