Unsere Scrape-API kombiniert einen Web-Datenextraktor, Universal-Scraper und Site-Parsing-API mit automatisierten Scraping-Funktionen. Sammeln, analysieren und nutzen Sie Daten aus dem gesamten Web mühelos, um umsetzbare Erkenntnisse zu gewinnen und fundiertere Geschäftsentscheidungen zu treffen. Diese leistungsstarke API ist für Entwickler, Marketer und Unternehmen konzipiert, die skalierbare, strukturierte Echtzeitdaten benötigen.
Scrape API ist ein leistungsstarkes Tool, das es Nutzern ermöglicht, Webdaten schnell aus dem Internet zu extrahieren. Mit nur einer API-Anfrage übernimmt die Scrape API automatisch die Datenextraktion, Anti-Scraping-Mechanismen, IP-Proxys und andere technische Herausforderungen, liefert strukturierte Daten und erspart den Nutzern das Codieren.
Einsatzmöglichkeiten der Scrape API
Von Marktforschung bis SEO – sehen Sie, wie unsere API reale Anwendungen ermöglicht
E-Commerce
Mit der Scrape API können Sie das Extrahieren von Produktinformationen von Wettbewerber-Websites automatisieren. Dadurch können Sie Markttrends in Echtzeit verfolgen und flexibel auf Preisänderungen reagieren.
Marktforschung
Die Scrape API unterstützt Sie beim Extrahieren von Daten wie branchenbezogenen Artikeln, Kommentaren und Fragen aus unterschiedlichen Informationsquellen (z.B. Nachrichtenseiten, soziale Medien, Foren etc.) für die Analyse.
SEO & Digitales Marketing
Die Scrape API kann Suchergebnisse (SERPs) auslesen und Ihnen helfen, z. B. Rankings, Keywords und Werbedaten Ihrer Wettbewerber zu extrahieren und so Ihre SEO-Strategie zu verbessern.
News-Aggregation
Die Scrape API unterstützt das Extrahieren von Inhalten aus verschiedenen Nachrichten-Websites, Blogs, Foren und sozialen Medien, sodass Sie stets in Echtzeit auf Schlagzeilen, Finanzberichte oder Social-Media-Updates zugreifen können.
Wie funktioniert die Scrape API?
Datenextraktion ganz einfach – mit nur wenigen Codezeilen
Schritt 1: Initiieren Sie eine API-Anfrage und übergeben Sie die Informationen der zu verarbeitenden Webseite über eine einfache URL.
Schritt 2: Der Server ruft den Seiteninhalt ab und liefert strukturierte Daten (z. B. JSON, CSV usw.) zurück.
Schritt 3: Analysieren Sie die Daten, gewinnen Sie die benötigten Informationen und führen Sie weitere Analysen oder Präsentationen durch.
Flexible Preise
Transparente Web-Scraping-Preise mit flexiblen API-Abonnement-Plänen. Vergleichen Sie Datenextraktionskosten, kaufen Sie Crawler-Zugang und starten Sie kostenlos — dann skalieren Sie nach Bedarf.
Monatlich
Jährlich Beliebt
Skalierungs-Tarife
High-Volume-Tarife für Teams mit hohem Bedarf und dediziertem Support.
Profitieren Sie von höheren Raten, mehr gleichzeitigen Browsern und Prioritätssupport.
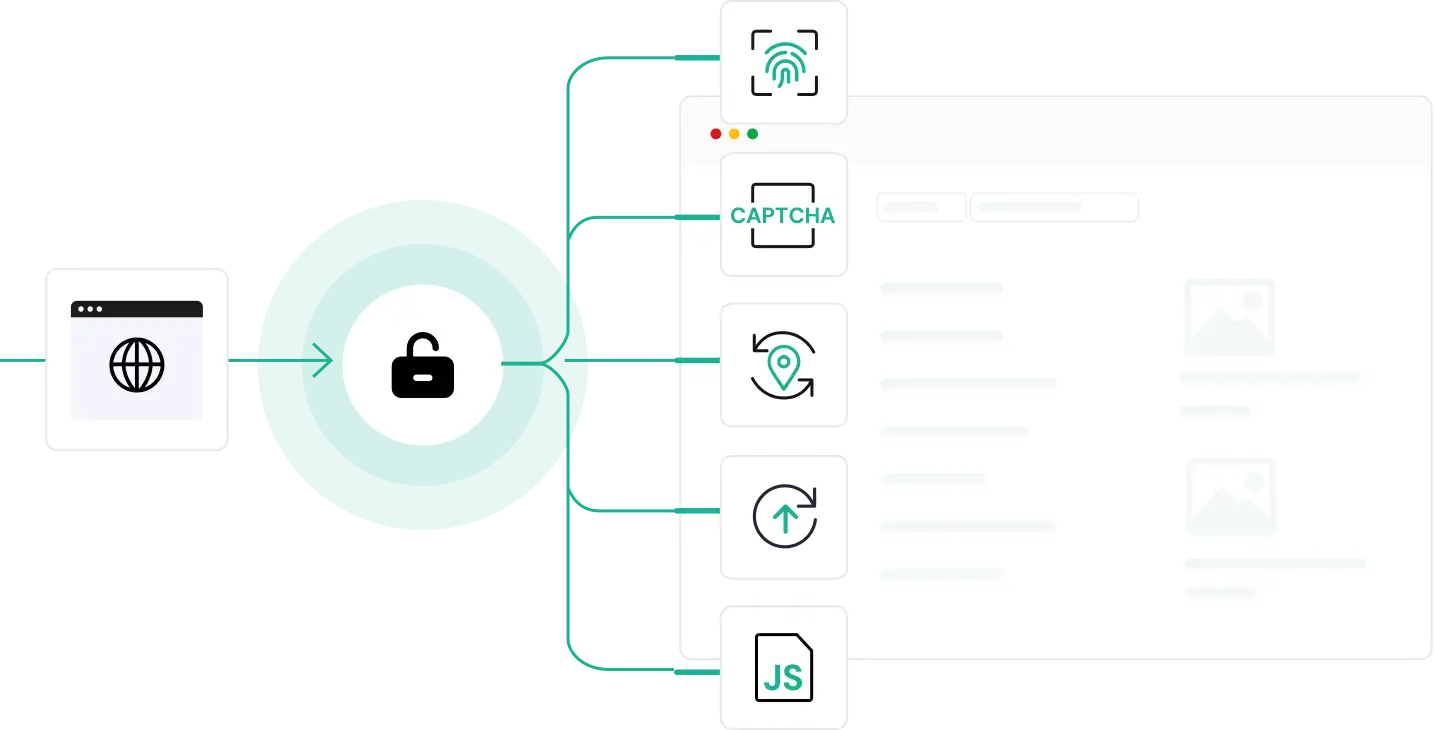
Umgeht automatisch CAPTCHAs, Login-Prüfungen, IP-Sperren und mehr – keine manuelle Intervention nötig.
IP-Rotation & Browser-Fingerprint-Emulation
IP-Adressen werden in Echtzeit rotiert und echte Browser-Fingerprints simuliert, um menschliches Verhalten zu imitieren und Bot-Erkennung zu vermeiden.
Unterstützung für JS-Rendering
Extrahieren Sie mühelos Inhalte von JavaScript-intensiven Websites mit integriertem dynamischem Rendering.
Hohe Erfolgsquote & Stabilität
Integrierte Proxy-Rotation und automatische Wiederholungen sorgen für bis zu 99 % Erfolgsquote.
Bezahlung nur bei Erfolg
Abgerechnet wird nur bei erfolgreicher Datenextraktion – das reduziert Ihre Scraping-Kosten um bis zu 30 %.
Garantierte Datenintegrität
Strenge Validierungsprozesse sorgen dafür, dass Sie saubere, strukturierte und einsatzbereite Geschäftsdaten erhalten.
Bereit, mit XCrawl zu starten?
Schließen Sie sich Entwicklern an, die XCrawl nutzen, um KI-Anwendungen mit strukturierten Webdaten zu betreiben. Starten Sie mit 1.000 kostenlosen Credits.
Hohe Scraping-Präzision auch auf JS-lastigen Plattformen.
Nora Alvarez
AI Analyst
★★★★★
5.0
Die Schnelligkeit der XCrawl-Scraping-API ist unübertroffen. Perfekt für hochfrequentes Crawlen.
Adam Fox
Backend Developer
★★★★★
4.6
Wir sammeln Wettbewerber-Content in Echtzeit – das hilft unserer Strategie enorm.
Julia Simmons
Digital Researcher
★★★★★
5.0
E-Commerce-Seiten werden fehlerlos gescrapet. Besser als unser Headless-Browser-Setup.
Dylan Hunt
Web Automation Lead
★★★★★
4.9
XCrawl löst IP-Rotation, Fingerprints und JS-Parsing automatisch.
Ava Quinn
Engineer
★★★★★
4.7
Die SERP-API liefert uns täglich verlässliche Rankingdaten.
Gavin Blake
SEO Developer
★★★★★
5.0
Bot-Blockaden machen uns keine Sorgen mehr. XCrawl löst das für uns.
Scarlett Wood
Data Operator
★★★★★
4.9
Unsere Workflows laufen seit dem Wechsel zu XCrawl deutlich reibungsloser.
Caleb Ortiz
Automation Specialist
★★★★★
4.8
Strukturierte Ausgabe spart uns jede Woche Stunden an Nachbearbeitung.
Bella Harmon
Technical Analyst
ISO 27001
CDPR
Von Nutzern am besten bewertet
Leader
Am einfachsten zu nutzen
Best Value Award
Häufig gestellte Fragen
Alles, was Sie über XCrawl wissen müssen.
Was ist XCrawl?
XCrawl ist eine KI-bereite Web-Scraping-API, die Webseiten in strukturiertes JSON, Markdown, HTML und Screenshots umwandelt. Für Entwickler sind integrierte Proxys, Crawling und SERP-Daten enthalten.
Wodurch unterscheidet sich XCrawl von anderen Web-Scraping-Tools?
Traditionelle Scraper liefern oft rohes HTML. XCrawl liefert sauberes JSON und Markdown sowie integrierte Proxy-Rotation, SERP-API und Integrationen mit MCP, n8n und Zapier für schnellere Produktions-Workflows.
Ist XCrawl kostenlos testbar?
Ja. Jedes neue Konto enthält 1.000 kostenlose Credits, ohne dass eine Kreditkarte erforderlich ist. So können Sie Scraping, Crawling, SERP-Daten und KI-bereite Ausgaben vor dem Upgrade testen.
Kann XCrawl JavaScript-lastige Webseiten scrapen?
Ja. XCrawl nutzt Headless-Browser-Rendering, um SPAs, unendliches Scrollen und dynamische Client-Seiten zu verarbeiten; die Daten werden nach dem Laden der Schlüsselelemente extrahiert.
Welche Ausgabeformate unterstützt XCrawl?
XCrawl liefert strukturiertes JSON, KI-bereites Markdown, rohes HTML und Screenshots. Nutzen Sie JSON für Systemintegration und Markdown für token-effiziente LLM-Workflows.
Mit welchen Programmiersprachen kann man XCrawl nutzen?
XCrawl ist eine REST-API und funktioniert mit jeder Sprache. Offizielle SDKs gibt es für Python und Node.js/TypeScript, Beispiele für Go, Ruby, PHP und cURL sind verfügbar.
Funktioniert XCrawl mit KI-Agenten und Automatisierungstools?
Ja. XCrawl unterstützt MCP für Claude sowie n8n, Zapier, Make und eigene Pipelines, damit KI-Agenten in Echtzeit auf aktuelle Webdaten zugreifen können.
Wie kann ich mit XCrawl starten?
Erstellen Sie ein kostenloses Konto auf xcrawl.com, kopieren Sie Ihren API-Schlüssel aus dem Dashboard und senden Sie Ihre erste Anfrage. Sie erhalten 1.000 kostenlose Credits und Schnellstart-Beispiele für Python, Node.js und cURL.
Wie funktionieren Preise und Credits bei XCrawl?
Jede Anfrage verbraucht Credits je nach Komplexität. Standardseiten, SERP-Anfragen und fortgeschrittene Funktionen verbrauchen unterschiedlich viele Credits. Prüfen Sie die Preisseite für die aktuelle Credit-Tabelle.
Brauche ich Programmierkenntnisse, um XCrawl zu nutzen?
Nein. Sie können XCrawl über No-Code-Plattformen wie n8n und Zapier verwenden oder SDKs und REST-Aufrufe für fortgeschrittene Entwickler-Workflows nutzen.
Holen Sie sich die Daten, die Sie brauchen.
Wir übernehmen die Datenerfassung, während Sie sich auf Ihre Arbeit konzentrieren.