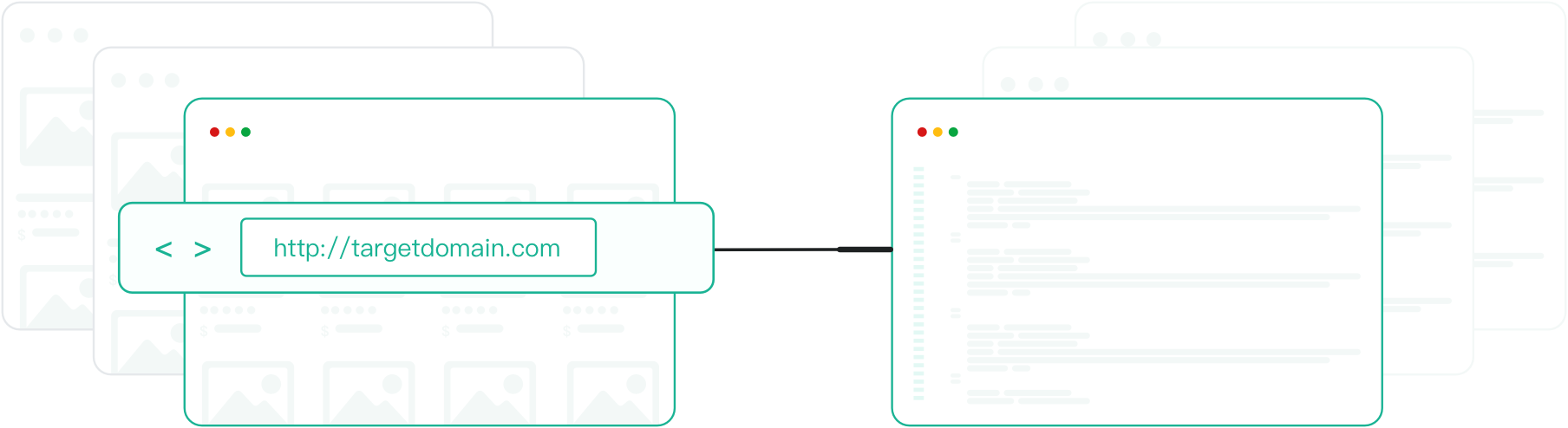
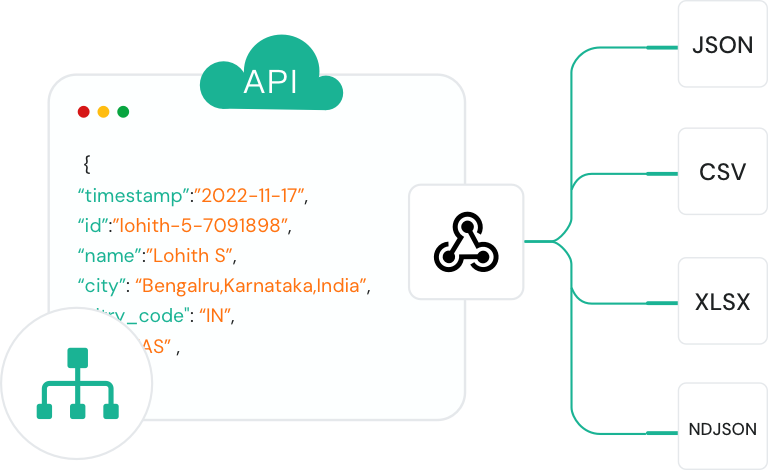
Unsere Crawl-API kombiniert HTML-Extraktions-API, Raw-Page-Scraper und Headless-Browser-API in einer einheitlichen Web-Crawler-Schnittstelle. Konzipiert für großangelegte und wiederkehrende Webdatenerfassung, ermöglicht diese Crawl-API Ihnen, Crawl-Regeln einmal zu definieren und automatisch strukturierte Daten über Tausende oder Millionen von Seiten zu sammeln.
Die Crawl-API ermöglicht es Entwicklern und Datenteams, ganze Websites oder große URL-Sets programmatisch zu crawlen.
Sie verwaltet Crawling-Logik, Anforderungsplanung und Anti-Bot-Schutz, sodass Sie sich auf die Datenextraktion statt auf die Infrastruktur konzentrieren können.
Crawl-API Anwendungsfälle
Automatisieren Sie großangelegte Datenerfassung im gesamten Web
Webdatenerfassung
Die Crawl-API ermöglicht es Teams, große Mengen öffentlicher Webdaten über ganze Websites hinweg zu sammeln. Sie ist ideal für den Aufbau von Datensätzen, die eine vollständige Website-Abdeckung erfordern, wie Produktkataloge, Artikelarchive oder verzeichnisartige Inhalte.
Markt- und Wettbewerbsintelligenz
Durch kontinuierliches Crawlen von Wettbewerber-Websites können Unternehmen Preisänderungen, Inhaltsaktualisierungen und Produkteinführungen im Laufe der Zeit überwachen. Die Crawl-API macht es einfach, Trends zu erkennen und schnell auf Marktbewegungen zu reagieren.
SEO & Website-Analyse
Die Crawl-API hilft SEO-Teams, Website-Struktur, interne Links, Metadaten und Indexierbarkeit im großen Maßstab zu analysieren. Durch das Crawlen großer Seitenzahlen können Teams technische Probleme identifizieren und die Website-Leistung effektiver optimieren.
KI & Datenpipelines
Die Crawl-API unterstützt langfristige Datenerfassung für KI- und maschinelle Lern-Workflows. Gecrawlte Daten können gespeichert, nach einem Zeitplan aktualisiert und für das Training von Modellen, Wissensbasen oder großangelegte Analysen verwendet werden.
Wie funktioniert die Crawl-API?
Datenextraktion ganz einfach – mit nur wenigen Codezeilen
Schritt1 Crawl-Umfang definieren
Schritt2 API verwaltet Crawling
Schritt3 Websites im großen Maßstab crawlen
Schritt4 Strukturierte Daten empfangen
Flexible Preise
Transparente Web-Scraping-Preise mit flexiblen API-Abonnement-Plänen. Vergleichen Sie Datenextraktionskosten, kaufen Sie Crawler-Zugang und starten Sie kostenlos — dann skalieren Sie nach Bedarf.
Monatlich
Jährlich Beliebt
Skalierungs-Tarife
High-Volume-Tarife für Teams mit hohem Bedarf und dediziertem Support.
Profitieren Sie von höheren Raten, mehr gleichzeitigen Browsern und Prioritätssupport.
Entwickelt für das effiziente und zuverlässige Crawlen von Tausenden bis Millionen von Seiten.
Regelbasierte Steuerung
Feinkörnige Kontrolle über Crawl-Umfang, Tiefe und Planung über API.
Anti-Bot-Schutz
Integrierte Proxy-Rotation und Anforderungsoptimierung zur Vermeidung von Blockierungen und Sperren.
Stabile Leistung im großen Maßstab
Konsistente Crawling-Leistung auch bei hoher Parallelität und lang laufenden Jobs.
Einfache Integration
Einfaches API-Design mit klarer Dokumentation für schnelle Einrichtung und Steuerung.
KI-bereite Datenausgabe
Strukturierte Crawl-Daten geeignet für Analysen, Data Warehouses und KI-Workflows.
Bereit, mit XCrawl zu starten?
Schließen Sie sich Entwicklern an, die XCrawl nutzen, um KI-Anwendungen mit strukturierten Webdaten zu betreiben. Starten Sie mit 1.000 kostenlosen Credits.
Hohe Scraping-Präzision auch auf JS-lastigen Plattformen.
Nora Alvarez
AI Analyst
★★★★★
5.0
Die Schnelligkeit der XCrawl-Scraping-API ist unübertroffen. Perfekt für hochfrequentes Crawlen.
Adam Fox
Backend Developer
★★★★★
4.6
Wir sammeln Wettbewerber-Content in Echtzeit – das hilft unserer Strategie enorm.
Julia Simmons
Digital Researcher
★★★★★
5.0
E-Commerce-Seiten werden fehlerlos gescrapet. Besser als unser Headless-Browser-Setup.
Dylan Hunt
Web Automation Lead
★★★★★
4.9
XCrawl löst IP-Rotation, Fingerprints und JS-Parsing automatisch.
Ava Quinn
Engineer
★★★★★
4.7
Die SERP-API liefert uns täglich verlässliche Rankingdaten.
Gavin Blake
SEO Developer
★★★★★
5.0
Bot-Blockaden machen uns keine Sorgen mehr. XCrawl löst das für uns.
Scarlett Wood
Data Operator
★★★★★
4.9
Unsere Workflows laufen seit dem Wechsel zu XCrawl deutlich reibungsloser.
Caleb Ortiz
Automation Specialist
★★★★★
4.8
Strukturierte Ausgabe spart uns jede Woche Stunden an Nachbearbeitung.
Bella Harmon
Technical Analyst
ISO 27001
CDPR
Von Nutzern am besten bewertet
Leader
Am einfachsten zu nutzen
Best Value Award
Häufig gestellte Fragen
Alles, was Sie über XCrawl wissen müssen.
Was ist XCrawl?
XCrawl ist eine KI-bereite Web-Scraping-API, die Webseiten in strukturiertes JSON, Markdown, HTML und Screenshots umwandelt. Für Entwickler sind integrierte Proxys, Crawling und SERP-Daten enthalten.
Wodurch unterscheidet sich XCrawl von anderen Web-Scraping-Tools?
Traditionelle Scraper liefern oft rohes HTML. XCrawl liefert sauberes JSON und Markdown sowie integrierte Proxy-Rotation, SERP-API und Integrationen mit MCP, n8n und Zapier für schnellere Produktions-Workflows.
Ist XCrawl kostenlos testbar?
Ja. Jedes neue Konto enthält 1.000 kostenlose Credits, ohne dass eine Kreditkarte erforderlich ist. So können Sie Scraping, Crawling, SERP-Daten und KI-bereite Ausgaben vor dem Upgrade testen.
Kann XCrawl JavaScript-lastige Webseiten scrapen?
Ja. XCrawl nutzt Headless-Browser-Rendering, um SPAs, unendliches Scrollen und dynamische Client-Seiten zu verarbeiten; die Daten werden nach dem Laden der Schlüsselelemente extrahiert.
Welche Ausgabeformate unterstützt XCrawl?
XCrawl liefert strukturiertes JSON, KI-bereites Markdown, rohes HTML und Screenshots. Nutzen Sie JSON für Systemintegration und Markdown für token-effiziente LLM-Workflows.
Mit welchen Programmiersprachen kann man XCrawl nutzen?
XCrawl ist eine REST-API und funktioniert mit jeder Sprache. Offizielle SDKs gibt es für Python und Node.js/TypeScript, Beispiele für Go, Ruby, PHP und cURL sind verfügbar.
Funktioniert XCrawl mit KI-Agenten und Automatisierungstools?
Ja. XCrawl unterstützt MCP für Claude sowie n8n, Zapier, Make und eigene Pipelines, damit KI-Agenten in Echtzeit auf aktuelle Webdaten zugreifen können.
Wie kann ich mit XCrawl starten?
Erstellen Sie ein kostenloses Konto auf xcrawl.com, kopieren Sie Ihren API-Schlüssel aus dem Dashboard und senden Sie Ihre erste Anfrage. Sie erhalten 1.000 kostenlose Credits und Schnellstart-Beispiele für Python, Node.js und cURL.
Wie funktionieren Preise und Credits bei XCrawl?
Jede Anfrage verbraucht Credits je nach Komplexität. Standardseiten, SERP-Anfragen und fortgeschrittene Funktionen verbrauchen unterschiedlich viele Credits. Prüfen Sie die Preisseite für die aktuelle Credit-Tabelle.
Brauche ich Programmierkenntnisse, um XCrawl zu nutzen?
Nein. Sie können XCrawl über No-Code-Plattformen wie n8n und Zapier verwenden oder SDKs und REST-Aufrufe für fortgeschrittene Entwickler-Workflows nutzen.
Holen Sie sich die Daten, die Sie brauchen.
Wir übernehmen die Datenerfassung, während Sie sich auf Ihre Arbeit konzentrieren.